
IMGT Repertoire (RPI)
Other B7 Family entries
IMGT RPI entry from gene to protein for Homo sapiens B7A2
Citing IMGT RPI entry for B7A2
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens B7A2
- IMGT gene definition: CD86 antigen (CD28 antigen ligand 2, B7-2 antigen)
Chromosomal localization
- Chromosome: 3
- Chromosomal localization: 3q21
Gene exon/intron organization
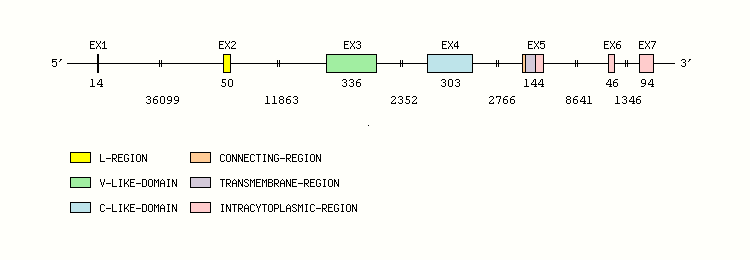
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 2
IMGT reference alleles
| Allele names | Gene functionality | Clone names | IMGT reference sequences | ||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||
| B7A2*01 | F | EX1 | U17715 [1] | gDNA | |
| EX2 | U17717 | ||||
| EX3 | U17718 | ||||
| EX4 | U17719 | ||||
| EX5 | U17720 | ||||
| EX6 | U17721 | ||||
| EX7 | U17722 | ||||
| B7A2*02 | F | EX1-EX7 | L25259 [2] | cDNA (1) | |
IMGT reference sequences (in FASTA format) for the allele(s): B7A2*01 to B7A2*02
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| B7A2*02 | F | EX1-EX7 | EF064748 | gDNA |
| U04343 | cDNA | |||
| BC040261 | ||||
| NM_005191 | ||||
| EX2-EX7 | CR541844 | cDNA splicing B (3) | ||
| NM_006889 | ||||
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| B7A2*01 | U17715 | 329 aa | 1 | |
| U17717 | 329 aa | 1 | ||
| U17718 | 329 aa | 1 | ||
| U17719 | 329 aa | 1 | ||
| U17720 | 329 aa | 1 | ||
| U17721 | 329 aa | 1 | ||
| U17722 | 329 aa | 1 | ||
| B7A2*02 | L25259 | P42081 | 329 aa | 1 |
| NM_005191 | NP_008820 | 329 aa | 1 | |
| NM_006889 | NP_787058 | 323 aa | 2 | |
IMGT notes:
- (1) In EX3 [D1], g28>a; E10>K, positions are according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN.
- (2) No EX1. Utilizes alterative start codon located 4 bases after 5' ACCEPTOR-SPLICE site in EX2.
IMGT references:
- [1] Jellis,C.L., et al., Immunogenetics 42, 85-89 (1995). PMID:7541777
- [2] Freeman,G.J., et al. Science 262, 909-911 (1993). PMID:7694363
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
B7A2*01: U17715(g) U17717(g) U17718(g) U17719(g) U17720(g) U17721(g) U17722(g)
Nucleotide sequence
1 atggatcccc agtgcactat gggactgagt aacattctct ttgtgatggc cttcctgctc 61 tctggtgctg ctcctctgga gattcaagct tatttcaatg agactgcaga cctgccatgc 121 caatttgcaa actctcaaaa ccaaagcctg agtgagctag tagtattttg gcaggaccag 181 gaaaacttgg ttctgaatga ggtatactta ggcaaagaga aatttgacag tgttcattcc 241 aagtatatgg gccgcacaag ttttgattcg gacagttgga ccctgagact tcacaatctt 301 cagatcaagg acaagggctt gtatcaatgt atcatccatc acaaaaagcc cacaggaatg 361 attcgcatcc accagatgaa ttctgaactg tcagtgcttg ctaacttcag tcaacctgaa 421 atagtaccaa tttctaatat aacagaaaat gtgtacataa atttgacctg ctcatctata 481 cacggttacc cagaacctaa gaagatgagt gttttgctaa gaaccaagaa ttcaactatc 541 gagtatgatg gtattatgca gaaatctcaa gataatgtca cagaactgta cgacgtttcc 601 atcagcttgt ctgtttcatt ccctgatgtt acgagcaata tgaccatctt ctgtattctg 661 gaaactgaca agacgcggct tttatcttca cctttctcta tagagcttga ggaccctcag 721 cctcccccag accacattcc ttggattaca gctgtacttc caacagttat tatatgtgtg 781 atggttttct gtctaattct atggaaatgg aagaagaaga agcggcctcg caactcttat 841 aaatgtggaa ccaacacaat ggagagggaa gagagtgaac agaccaagaa aagagaaaaa 901 atccatatac ctgaaagatc tgatgaagcc cagcgtgttt ttaaaagttc gaagacatct 961 tcatgcgaca aaagtgatac atgtttttaa
Nucleotide sequence in FASTA format (without gaps)
B7A2*01
Amino acid sequence
1 MDPQCTMGLS NILFVMAFLL SGAAPLEIQA YFNETADLPC QFANSQNQSL SELVVFWQDQ 61 ENLVLNEVYL GKEKFDSVHS KYMGRTSFDS DSWTLRLHNL QIKDKGLYQC IIHHKKPTGM 121 IRIHQMNSEL SVLANFSQPE IVPISNITEN VYINLTCSSI HGYPEPKKMS VLLRTKNSTI 181 EYDGIMQKSQ DNVTELYDVS ISLSVSFPDV TSNMTIFCIL ETDKTRLLSS PFSIELEDPQ 241 PPPDHIPWIT AVLPTVIICV MVFCLILWKW KKKKRPRNSY KCGTNTMERE ESEQTKKREK 301 IHIPERSDEA QRVFKSSKTS SCDKSDTCF*
Amino acid sequence in FASTA format (without gap)
B7A2*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN on one layer, V-LIKE-DOMAIN on two layers, C-LIKE-DOMAIN on one layer, C-LIKE-DOMAIN on two layers
IMGT databases
External links
Nomenclature
- HGNC: 1705
Genome databases
- Entrez Gene: 942
- GENATLAS: 3079
- GeneCards: GC03P123256
- GDB: 433597
- OMIM: 601020
Sequence database
- EMBL: U17715, U17717, U17718, U17719, U17720, U17721, U17722, L25259, DQ893787, EF064748, U04343, BC040261, CR541844
- GenBank: U17715, U17717, U17718, U17719, U17720, U17721, U17722, L25259, DQ893787, EF064748, U04343, BC040261, CR541844
- DDBJ: U17715, U17717, U17718, U17719, U17720, U17721, U17722, L25259, DQ893787, EF064748, U04343, BC040261, CR541844
- Swiss-Prot: P42081
- TrEMBL:
- NCBI: NM_005191, NM_006889
Structure database
Created: 23/05/2007
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2024 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT