
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Homo sapiens CD1A
IMGT gene name and definition
- IMGT gene name: Homo sapiens CD1A
- IMGT gene definition: CD1A antigen, a polypeptide (CD1A)
Chromosomal localization
- Chromosome: 1
- Chromosomal localization: 1q22-q23
Gene exon/intron organization
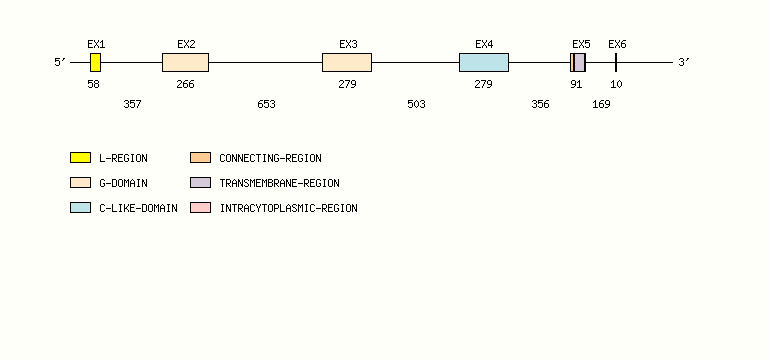
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 3
IMGT reference alleles
| Allele name | Gene functionality | reference sequences | ||
|---|---|---|---|---|
| Clone names | Accession numbers | Molecule type | ||
| CD1A*01 | F | lambda-R4B3 | M22080 | gDNA (EX1) |
| M22163 | gDNA (EX2) | |||
| M22164 | gDNA (EX3) | |||
| M22165 | gDNA (EX4) | |||
| M22166 | gDNA (EX5) | |||
| M22167 | gDNA (EX6) | |||
| CD1A*02 | F | M28825 | cDNA | |
| CD1A*03 | F | X04450 | cDNA (1) |
IMGT reference sequences (in FASTA format) for the allele(s): CD1A*01 to CD1A*03
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele name | Gene functionality | reference sequences | ||
|---|---|---|---|---|
| Clone names | Accession numbers | Molecule type | ||
| CD1A*01 | F | RP11-101J8 | AL121986 | gDNA |
| AF142665 | cDNA (2) |
Corresponding protein database accession numbers
| Allele name | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| CD1A*01 | M22080 | 20 aa | ||
| M22163 to M22167 | 307 aa | |||
| AL121986 | 327 aa | |||
| AF142665 (2) | 91 aa | |||
| CD1A*02 | NM_00763 | NP_001754 | 327 aa | |
| M28825 | Sw: P06126 | 327 aa | ||
| CD1A*03 | X04450 (1) | Sw: P06126 | 229 aa (1) | |
IMGT notes:
- (1) partial cds, from EX3
- (2) partial cds, only EX2
Genomic sequence
Position: 1084...4105 (from ATG to stop codon included).Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
CD1A*01: AL121986(g)
Nucleotide sequence
1 atgctgtttt tgctacttcc attgttagct gttctcccag gtgatggcaa tgcagacggg 61 ctcaaggagc ctctctcctt ccatgtcacc tggatcgcat ccttttacaa ccattcctgg 121 aaacaaaatc tggtctcagg ttggctgagt gatttgcaga ctcatacctg ggacagcaat 181 tccagcacca tcgttttcct gtgcccctgg tccaggggaa acttcagcaa tgaggagtgg 241 aaggaactgg aaacattatt ccgtatacgc accattcggt catttgaggg aattcgtaga 301 tacgcccatg aattgcagtt tgaatatcct tttgagatac aggtgacagg aggctgtgag 361 ctgcactctg gaaaggtctc aggaagcttc ttgcagttag cttatcaagg atcagacttt 421 gtgagcttcc agaacaattc atggttgcca tatccagtgg ctgggaatat ggccaagcat 481 ttctgcaaag tgctcaatca gaatcagcat gaaaatgaca taacacacaa tcttctcagt 541 gacacctgcc cacgtttcat cttgggtctt cttgatgcag gaaaggcaca tctccagcgg 601 caagtgaagc ccgaggcctg gctgtcccat ggccccagtc ctggccctgg ccatctgcag 661 cttgtgtgcc atgtctcagg attctaccca aagcccgtgt gggtgatgtg gatgcggggt 721 gagcaggagc agcagggcac tcagcgaggg gacatcttgc ccagtgctga tgggacatgg 781 tatctccgcg caaccctgga ggtggccgct ggggaggcag ctgacctgtc ctgtcgggtg 841 aagcacagca gtctagaggg ccaggacatc gtcctctact gggagcatca cagttccgtg 901 ggcttcatca tcttggcggt gatagtgcct ttacttcttc tgataggtct tgcgctttgg 961 ttcaggaaac gctgtttctg ttaa
Nucleotide sequence in FASTA format (without gaps)
CD1A*01
Amino acid sequence
1 MLFLLLPLLA VLPGDGNADG LKEPLSFHVT WIASFYNHSW KQNLVSGWLS DLQTHTWDSN 61 SSTIVFLCPW SRGNFSNEEW KELETLFRIR TIRSFEGIRR YAHELQFEYP FEIQVTGGCE 121 LHSGKVSGSF LQLAYQGSDF VSFQNNSWLP YPVAGNMAKH FCKVLNQNQH ENDITHNLLS 181 DTCPRFILGL LDAGKAHLQR QVKPEAWLSH GPSPGPGHLQ LVCHVSGFYP KPVWVMWMRG 241 EQEQQGTQRG DILPSADGTW YLRATLEVAA GEAADLSCRV KHSSLEGQDI VLYWEHHSSV 301 GFIILAVIVP LLLLIGLALW FRKRCFC*
Amino acid sequence in FASTA format (without gap)
CD1A*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays: C-LIKE-DOMAIN
- Protein displays (MHC): G-LIKE-ALPHA1 [D1], G-LIKE-ALPHA2 [D2]
- IMGT Collier de perles: G-LIKE-DOMAINs on one layer, C-LIKE-DOMAIN on one layer, C-LIKE-DOMAIN on two layers
IMGT databases
- IMGT/3Dstructure-DB: 1onq
External links
Nomenclature
- HGNC: 1634
Genome databases
- EntrezGene: 909
- GENATLAS: 74
- GeneCards: GC01P155440
- GDB: GDB:120575
- OMIM: 188370
Sequence databases
- EMBL: AL121986, AF142665, M28825, M22167, M22080, M22163, M22164, M22165, M22166, X04450
- GenBank: AL121986, AF142665, M28825, M22167, M22080, M22163, M22164, M22165, M22166, X04450
- DDBJ: AL121986, AF142665, M28825, M22167, M22080, M22163, M22164, M22165, M22166, X04450
- Swiss-Prot: P06126
- TrEMBL:
- NCBI: NM_001763, NP_001754
Structure databases
- PDB: 1ONQ
Created: 18/10/2006
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Sandra Ghayad
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Sandra Ghayad
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2024 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT