
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Homo sapiens MOG
Citing IMGT RPI entry for MOG
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens MOG
- IMGT gene definition: Homo sapiens Myelin-oligodendrocyte glycoprotein
Chromosomal localization
- Chromosome: 6
- Chromosomal localization: 6p22.1
Gene exon/intron organization
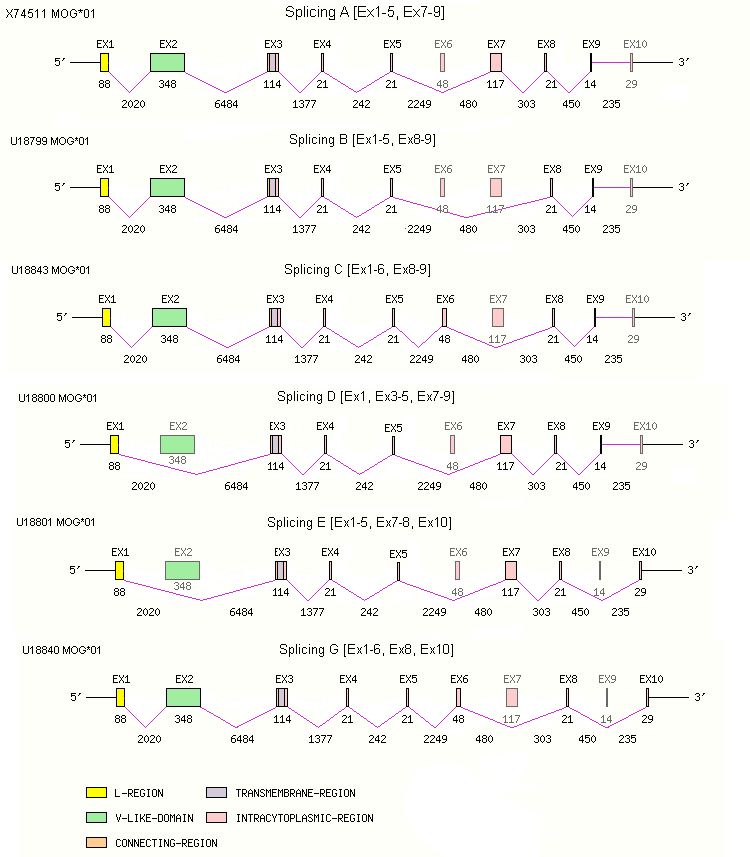
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 4
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| MOG*01 | F | EX1-5, 7-9 | X74511 [1] | cDNA |
| MOG*02 | F | EX1-5, 7-9 | Z48051 | gDNA (1) |
| MOG*03 | F | EX1-5, 7-9 | U64564 | cDNA(2) |
| MOG*04 | F | EX1-5, 7-9 | AL645936 | gDNA (3) |
IMGT reference sequences (in FASTA format) for the allele(s): MOG*01 to MOG*04
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| MOG*01 | F | EX1-5, 7-9 | AL929591 | gDNA |
| AL050328 | gDNA | |||
| BX120002 | gDNA | |||
| U18798 | cDNA splicing A | |||
| X74511 | cDNA splicing A | |||
| EX1-5, 8, 9 | U18799 | cDNA splicing B | ||
| EX1-6, 8, 9 | U18843 | cDNA splicing C | ||
| EX1, 3-5, 7-9 | U18800 | cDNA splicing D | ||
| EX1-5, 7, 8, 10 | U18801 | cDNA splicing E | ||
| AY566852 | cDNA splicing E | |||
| EX1-5, 8, 10 | U18803 | cDNA splicing F | ||
| EX1-6, 8, 10 | U18840 | cDNA splicing G | ||
Corresponding protein database accession numbers
| Allele Name | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| MOG*01 | X74511 | Q16653 | 247aa | 1 |
IMGT notes:
- (1) In EX1 15g>a.
- (2) In EX3 75g>c; 26V>L
- (3) In EX1 15g>a and EX3 84g>a.
IMGT references:
- [1] Hilton A.A. et al., J. Neurochem, 309-318 (1995). PMID:7790876
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
Nucleotide sequence
1 atggcaagct tatcgagacc ctctctgccc agctgcctct gctccttcct cctcctcctc 61 ctcctccaag tgtcttccag ctatgcaggg cagttcagag tgataggacc aagacaccct 121 atccgggctc tggtcgggga tgaagtggaa ttgccatgtc gcatatctcc tgggaagaac 181 gctacaggca tggaggtggg gtggtaccgc ccccccttct ctagggtggt tcatctctac 241 agaaatggca aggaccaaga tggagaccag gcacctgaat atcggggccg gacagagctg 301 ctgaaagatg ctattggtga gggaaaggtg actctcagga tccggaatgt aaggttctca 361 gatgaaggag gtttcacctg cttcttccga gatcattctt accaagagga ggcagcaatg 421 gaattgaaag tagaagatcc tttctactgg gtgagccctg gagtgctggt tctcctcgcg 481 gtgctgcctg tgctcctcct gcagatcact gttggcctcg tcttcctctg cctgcagtac 541 agactgagag gaaaacttcg agcagagata gagaatctcc accggacttt tgatccccac 601 tttctgaggg tgccctgctg gaagataacc ctgtttgtaa ttgtgccggt tcttggaccc 661 ttggttgcct tgatcatctg ctacaactgg ctacatcgaa gactagcagg gcaattcctt 721 gaagagctac gaaatccctt ctga
Nucleotide sequence in FASTA format (without gaps)
MOG*01
Amino acid sequence
1 MASLSRPSLP SCLCSFLLLL LLQVSSSYAG QFRVIGPRHP IRALVGDEVE LPCRISPGKN 61 ATGMEVGWYR PPFSRVVHLY RNGKDQDGDQ APEYRGRTEL LKDAIGEGKV TLRIRNVRFS 121 DEGGFTCFFR DHSYQEEAAM ELKVEDPFYW VSPGVLVLLA VLPVLLLQIT VGLVFLCLQY 181 RLRGKLRAEI ENLHRTFDPH FLRVPCWKIT LFVIVPVLGP LVALIICYNW LHRRLAGQFL 241 EELRNPF*
Amino acid sequence in FASTA format (without gap)
MOG*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN on one layer, V-LIKE-DOMAIN on two layers
IMGT databases
- IMGT/3Dstructure-DB: 1pko
External links
Nomenclature
- HGNC: 7197
Genome databases
- Entrez Gene: 4340
- GENATLAS: 3939
- GeneCards: GC06P029732
- GDB: 309079
- OMIM: 159465
Sequence databases
- EMBL: X74511, U18798, U18799, U18843, U18800, U18801, AY566852, U18803, U18840, Z48051, U64564, AL929591, AL050328, BX120002, AL645936
- GenBank: X74511, U18798, U18799, U18843, U18800, U18801, AY566852, U18803, U18840, Z48051, U64564, AL929591, AL050328, BX120002, AL645936
- DDBJ: X74511, U18798, U18799, U18843, U18800, U18801, AY566852, U18803, U18840, Z48051, U64564, AL929591, AL050328, BX120002, AL645936
- Swiss-Prot: Q16653
- TrEMBL:
- NCBI:
Structure database
- PDB: 1pko
Created: 17/07/2006
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Stéphanie Douvres, Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Stéphanie Douvres, Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2024 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT