
IMGT Repertoire (RPI)
Other CD2 Family entries
IMGT RPI entry from gene to protein for Mus musculus CD2
Citing IMGT RPI entry for CD2
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Mus musculus CD2
- IMGT gene definition: CD2 molecule
Chromosomal localization
- Chromosome: 3
- Chromosomal localization: 3 F2.2 48.2cM
Gene exon/intron organization
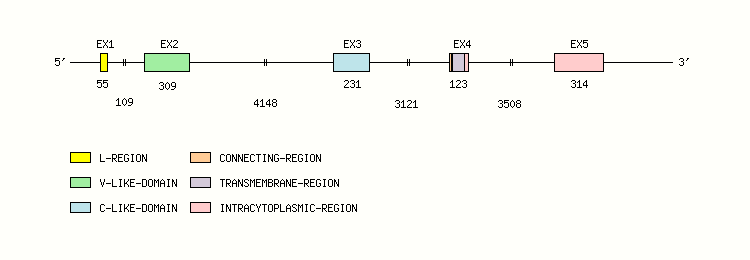
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 4
IMGT reference alleles
| Allele names | Gene functionality | Strain | IMGT reference sequences | ||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||
| CD2*01 | F | BALB/c | EX1-5 | M19799, M19801, M19803, M19805, M19807 [1] | gDNA |
| CD2*02 | F | EX1-5 | M18934 [2] | cDNA (1) | |
| CD2*03 | F | EX1-5 | AL672260 | gDNA (2) | |
| CD2*04 | F | EX1-5 | X06143 [3] | cDNA (3) | |
IMGT reference sequences (in FASTA format) for the allele(s): CD2*01 to CD2*04
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | Strain | IMGT reference sequences | ||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||
| CD2*01 | F | BALB/c | EX1-5 | AF065909 | cDNA |
| BALB/cByJ | EX1-5 | AF306543 | |||
| DBA/2J | EX1-5 | AF065906 | |||
| CD2*03 | F | NOD/LtJ | EX1-5 | AF065907 | cDNA |
| RIIIS/J | EX1-5 | AF065908 | |||
| C57BL/6NCrl | EX1-5 | BC053731 | |||
| B10.A | EX1-5 | Y00023 | |||
| EX1-5 | NM_013486 | ||||
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| CD2*01 | M19799, M19801, M19803, M19805, M19807 | P08920 | 344 aa | 1 |
| CD2*02 | M18934 | (1) | 344 aa | 1 |
| CD2*03 | AL672260 | Q5SRC1 | 344 aa | 1 |
| NM_013486 | NP_038514 | 344 aa | 1 | |
| CD2*04 | X06143 | (3) | 344 aa | 1 |
IMGT notes:
- (1) EX3[D2] c65>g; T22>L in C-LIKE-DOMAIN, numbering according to unique numbering for C-DOMAIN and C-LIKE-DOMAIN
- (2) EX3[D2] g20>a; V7>M, a145>g, g296>a; S99>N and c360>t; T120>M in C-LIKE-DOMAIN, numbering according to unique numbering for C-DOMAIN and C-LIKE-DOMAIN
- (3) EX3[D2] g20>a; V7>M, a145>g, g296>a; S99>N and g358>t, c360>t; T120>M in C-LIKE-DOMAIN, numbering according to unique numbering for C-DOMAIN and C-LIKE-DOMAIN
IMGT references:
- [1] Diamond D.J. et al, Proc. Natl. Acad. Sci. U.S.A. 85, 1615-1619 (1988). PMID:2894031
- [2] Yagita H. et al, J. Immunol. 140, 1321-1326 (1988). PMID:3257775
- [3] Clayton L.K. et al, Eur. J. Immunol. 17, 1367-1370 (1987). PMID:2820751
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
CD2*01: M19799(g) M19801(g) M19803(g) M19805(g) M19807(g)
Nucleotide sequence
1 atgaaatgta aattcctggg tagcttcttt ctgctcttca gcctttccgg caaaggggcg 61 gactgcagag acaatgagac catctggggt gtcttgggtc atggcatcac cctgaacatc 121 cccaactttc aaatgactga tgatattgat gaggtgcgat gggtaaggag gggcaccctg 181 gtcgcagagt ttaaaaggaa gaagccacct tttttgatat cagaaacgta tgaggtctta 241 gcaaacggat ccctgaagat aaagaagccg atgatgagaa acgacagtgg cacctataat 301 gtaatggtgt atggcacaaa tgggatgact aggctggaga aggacctgga cgtgaggatt 361 ctggagaggg tctcaaagcc cgtgatccac tgggaatgcc ccaacacaac cctgacctgt 421 gcggtcttgc aaggaacaga ttttgaactg aagctgtatc aaggggaaac actactcaat 481 agtctccccc agaagaacat gagttaccag tggaccaacc tgagcgcacc attcaagtgt 541 gaggcgataa acccggtcag caaggagtct aagacggaag ttgttaactg tccagagaaa 601 ggtctgtcct tctatgtcac agtgggggtc ggtgcaggag gactcctctt ggtgctcttg 661 gtggcgcttt ttattttctg tatctgcaag aggagaaaac ggaacaggag gagaaaagat 721 gaagagctgg aaataaaagc ttccagaaca agcactgtgg aaaggggccc caagccgcac 781 tcaaccccag ccgcagcagc gcagaattca gtggcgctcc aagctcctcc tccacctggc 841 catcacctcc agacacctgg ccatcgtccc ttgcctccag gccaccgtac ccgtgagcac 901 cagcagaaga agagacctcc tccatcaggc acacagattc accagcagaa aggccctcct 961 ttacccagac cccgagttca gccaaaacct ccctgtggga gtggagatgg tgtttcactg 1021 ccgcccccta attaa
Nucleotide sequence in FASTA format (without gaps)
CD2*01
Amino acid sequence
1 MKCKFLGSFF LLFSLSGKGA DCRDNETIWG VLGHGITLNI PNFQMTDDID EVRWVRRGTL 61 VAEFKRKKPP FLISETYEVL ANGSLKIKKP MMRNDSGTYN VMVYGTNGMT RLEKDLDVRI 121 LERVSKPVIH WECPNTTLTC AVLQGTDFEL KLYQGETLLN SLPQKNMSYQ WTNLSAPFKC 181 EAINPVSKES KTEVVNCPEK GLSFYVTVGV GAGGLLLVLL VALFIFCICK RRKRNRRRKD 241 EELEIKASRT STVERGPKPH STPAAAAQNS VALQAPPPPG HHLQTPGHRP LPPGHRTREH 301 QQKKRPPPSG TQIHQQKGPP LPRPRVQPKP PCGSGDGVSL PPPN*
Amino acid sequence in FASTA format (without gap)
CD2*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN, C-LIKE-DOMAIN
External links
Nomenclature
- HGNC:
Genome databases
Sequence database
- EMBL: M19799, M18934, AL672260, X06143, AF065909, AF306543, AF065906, AF065907, AF065908, BC053731, Y00023
- GenBank: M19799, M18934, AL672260, X06143, AF065909, AF306543, AF065906, AF065907, AF065908, BC053731, Y00023
- DDBJ: M19799, M18934, AL672260, X06143, AF065909, AF306543, AF065906, AF065907, AF065908, BC053731, Y00023
- Swiss-Prot: P08920
- TrEMBL: Q5SRC1
- NCBI: NM_013486, NP_038514
Structure database
- PDB:
Created: 23/05/2007
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2025 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT