
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Homo sapiens B7A1
Citing IMGT RPI entry for B7A1
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens B7A1
- IMGT gene definition: CD80 antigen
Chromosomal localization
- Chromosome: 3
- Chromosomal localization: 3q13.3-q21
Gene exon/intron organization
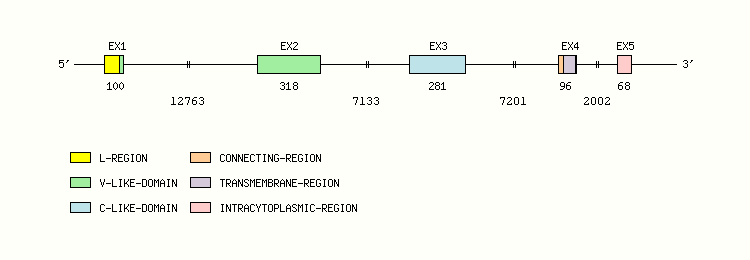
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 2
IMGT reference alleles
| Allele names | Gene functionality | Clone names | IMGT reference sequences | ||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||
| B7A1*01 | F | EX1 | M83072 | gDNA splicing A | |
| EX2 | M83073 | ||||
| EX3 | M83074 | ||||
| EX4 | M83075 | ||||
| EX5 | M83077 | ||||
| B7A1*02 | F | EX1-2 | AY081815 | cDNA (2) splicing C | |
IMGT reference sequences (in FASTA format) for the allele(s): B7A1*01 to B7A1*02
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| B7A1*01 | F | EX1-EX5 | M27533 | cDNA |
| BC042665 | cDNA | |||
| EX1-5 | NM_005191 | cDNA | ||
| EX1-EX3, EX5 | AY197778 | cDNA (1) splicing B | ||
| AY197777 | cDNA | |||
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| B7A1*01 | M83072 | P33681 | 288 aa | 1 |
| M83073 | 288 aa | 1 | ||
| M83074 | 288 aa | 1 | ||
| M83075 | 288 aa | 1 | ||
| M83077 | 288 aa | 1 | ||
| NM_005191 | NP_005182 | 288 aa | 1 | |
| B7A1*02 | AY081815 | 148 aa | 3 | |
IMGT notes:
- (1) Splicing B (251 aa). No EX4. New amino acid (T1>S) at position 1 due to alternative splicing in EX5.
- (2) Splicing C (148 aa). No EX3-5. EX2 has has no DONOR-SPLICE site and the transcript ends after 9 codons beyond the usual 3' splice site and a326>c; Y109>S, positions according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN.
IMGT references:
- [1] Selvakumar.A, et al. Immunogenetics 36, 175-181 (1992). PMID:1377173
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
B7A1*01: M83072(g) M83073(g) M83074(g) M83075(g) M83077(g)
Nucleotide sequence
1 atgggccaca cacggaggca gggaacatca ccatccaagt gtccatacct caatttcttt 61 cagctcttgg tgctggctgg tctttctcac ttctgttcag gtgttatcca cgtgaccaag 121 gaagtgaaag aagtggcaac gctgtcctgt ggtcacaatg tttctgttga agagctggca 181 caaactcgca tctactggca aaaggagaag aaaatggtgc tgactatgat gtctggggac 241 atgaatatat ggcccgagta caagaaccgg accatctttg atatcactaa taacctctcc 301 attgtgatcc tggctctgcg cccatctgac gagggcacat acgagtgtgt tgttctgaag 361 tatgaaaaag acgctttcaa gcgggaacac ctggctgaag tgacgttatc agtcaaagct 421 gacttcccta cacctagtat atctgacttt gaaattccaa cttctaatat tagaaggata 481 atttgctcaa cctctggagg ttttccagag cctcacctct cctggttgga aaatggagaa 541 gaattaaatg ccatcaacac aacagtttcc caagatcctg aaactgagct ctatgctgtt 601 agcagcaaac tggatttcaa tatgacaacc aaccacagct tcatgtgtct catcaagtat 661 ggacatttaa gagtgaatca gaccttcaac tggaatacaa ccaagcaaga gcattttcct 721 gataacctgc tcccatcctg ggccattacc ttaatctcag taaatggaat ttttgtgata 781 tgctgcctga cctactgctt tgccccaaga tgcagagaga gaaggaggaa tgagagattg 841 agaagggaaa gtgtacgccc tgtataa
Nucleotide sequence in FASTA format (without gaps)
B7A1*01
Amino acid sequence
1 MGHTRRQGTS PSKCPYLNFF QLLVLAGLSH FCSGVIHVTK EVKEVATLSC GHNVSVEELA 61 QTRIYWQKEK KMVLTMMSGD MNIWPEYKNR TIFDITNNLS IVILALRPSD EGTYECVVLK 121 YEKDAFKREH LAEVTLSVKA DFPTPSISDF EIPTSNIRRI ICSTSGGFPE PHLSWLENGE 181 ELNAINTTVS QDPETELYAV SSKLDFNMTT NHSFMCLIKY GHLRVNQTFN WNTTKQEHFP 241 DNLLPSWAIT LISVNGIFVI CCLTYCFAPR CRERRRNERL RRESVRPV*
Amino acid sequence in FASTA format (without gap)
B7A1*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN
- IMGT/3Dstructure-DB: 1i8l
- HGNC: 1700
- Entrez Gene: 941
- GENATLAS: 3607
- GeneCards: GC03M120725
- GDB: 251792
- OMIM: 112203
IMGT databases
External links
Nomenclature
Genome databases
Sequence database
Created: 23/05/2007
Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT