
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Mus musculus B7A2
Citing IMGT RPI entry for B7A2
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Mus musculus B7A2
- IMGT gene definition: CD86 antigen (CD28 antigen ligand 2, B7-2 antigen)
Chromosomal localization
- Chromosome: 16
- Chromosomal localization: 16 B5; 16 26.9 cM
Gene exon/intron organization
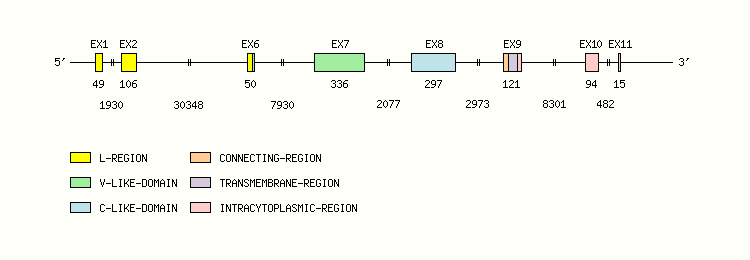
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 4
IMGT reference alleles
| Allele names | Gene functionality | Strains | IMGT reference sequences | ||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||
| B7A2*01 | F | 129 | EX1 | U39456[1] | gDNA |
| EX2 | U39457 | ||||
| EX6 | U39461 | ||||
| EX7 | U39462 | ||||
| EX8 | U39463 | ||||
| EX9 | U39464 | ||||
| EX10 | U39465 | ||||
| EX11 | U39466 | ||||
| B7A2*02 | F | NOD | EX4, 6-11 | AK172548 | cDNA (2) splicing B |
| B7A2*03 | F | NOD | EX4, 6-11 | AK170054 | cDNA (3) splicing B |
| B7A2*04 | F | CHECHII | EX4, 6-11 | BC013807 | cDNA (4) splicing B |
IMGT reference sequences (in FASTA format) for the allele(s): B7A2*01 to B7A2*04
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | Strains | IMGT reference sequences | ||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||
| B7A2*01 | F | C57BL/6J | EX3-EX8 | AF065898 | cDNA splicing B |
| EX3-EX8 | AK079513 | ||||
| B10.S/J | EX3-EX8 | AF065899 | |||
| SJL/J | EX3-EX8 | AF065900 | |||
| A/J | EX3-EX8 | AF065897 | |||
| EX3-EX8 | L25606 | ||||
| EX3-EX8 | S70108 | ||||
| B7A2*04 | F | EX3-EX8 | NM_019388 | cDNA splicing B | |
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| B7A2*01 | U39456 | Q64381 | 356 aa | 1 |
| U39457 | 356 aa | 1 | ||
| U39462 | 356 aa | 1 | ||
| U39463 | 356 aa | 1 | ||
| U39464 | 356 aa | 1 | ||
| U39465 | 356 aa | 1 | ||
| U39466 | 356 aa | 1 | ||
| B7A2*02 | AK172548 | Tr:Q3T9F8 | 309 aa | 2 |
| B7A2*03 | AK170054 | Tr:Q3TDR5 | 309 aa | 2 |
| B7A2*04 | BC013807 | Tr:Q91YV7 | 309 aa | 2 |
| NM_019388 | NP_062261 | 309 aa | 2 | |
IMGT notes:
- (1) Three alternative spliced transcripts are mentioned in PUBMED:7499829. Splicing A (356 aa) has exons EX1,2 and EX6-11. Splicing C (314 aa) has exons EX5 and EX7-11. Splicing B (309 aa) has exons EX4 and EX7-11. No cDNA is available for splicing C.
- (2) Splicing B. In EX8 [D2] a79>g; K26>R, positions according to IMGT unique numbering for C-DOMAIN and C-LIKE-DOMAIN.
- (3) Splicing B. In EX8 [D2] a288.4>g; K96.4>R, positions according to IMGT unique numbering for C-DOMAIN and C-LIKE-DOMAIN.
- (4) Splicing B. Five nucleotide variations in EX7 [D1], EX8 [D2] and EX9.
IMGT references:
- [1] Borriello,F. et al. J. Immunol. 155, 5490-5497 (1995). PMID:7499829
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
B7A2*01: U39456(g) U39457(g) U39461(g) U39462(g) U39463(g) U39464(g) U39465(g) U39466(g)
Nucleotide sequence
1 atggccaaaa ctatccggag actctcggtg gcctttttga cactctcaga caggggaccc 61 cattataaga tcctcctacc tctacctcac aagggctgga ctccaggcct gacccacaat 121 gcctctctct actgtgcctc gatcatttta aaaaacacca tgggcttggc aatccttatc 181 tttgtgacag tcttgctgat ctcagatgct gtttccgtgg agacgcaagc ttatttcaat 241 gggactgcat atctgccgtg cccatttaca aaggctcaaa acataagcct gagtgagctg 301 gtagtatttt ggcaggacca gcaaaagttg gttctgtacg agcactattt gggcacagag 361 aaacttgata gtgtgaatgc caagtacctg ggccgcacga gctttgacag gaacaactgg 421 actctacgac ttcacaatgt tcagatcaag gacatgggct cgtatgattg ttttatacaa 481 aaaaagccac ccacaggatc aattatcctc caacagacat taacagaact gtcagtgatc 541 gccaacttca gtgaacctga aataaaactg gctcagaatg taacaggaaa ttctggcata 601 aatttgacct gcacgtctaa gcaaggtcac ccgaaaccta agaagatgta ttttctgata 661 actaattcaa ctaatgagta tggtgataac atgcagatat cacaagataa tgtcacagaa 721 ctgttcagta tctccaacag cctctctctt tcattcccgg atggtgtgtg gcatatgacc 781 gttgtgtgtg ttctggaaac ggagtcaatg aagatttcct ccaaacctct caatttcact 841 caagagtttc catctcctca aacgtattgg aaggagatta cagcttcagt tactgtggcc 901 ctcctccttg tgatgctgct catcattgta tgtcacaaga agccgaatca gcctagcagg 961 cccagcaaca cagcctctaa gttagagcgg gatagtaacg ctgacagaga gactatcaac 1021 ctgaaggaac ttgaacccca aattgcttca gcaaaaccaa atgcagagtg a
Nucleotide sequence in FASTA format (without gaps)
B7A2*01
Amino acid sequence
1 MAKTIRRLSV AFLTLSDRGP HYKILLPLPH KGWTPGLTHN ASLYCASIIL KNTMGLAILI 61 FVTVLLISDA VSVETQAYFN GTAYLPCPFT KAQNISLSEL VVFWQDQQKL VLYEHYLGTE 121 KLDSVNAKYL GRTSFDRNNW TLRLHNVQIK DMGSYDCFIQ KKPPTGSIIL QQTLTELSVI 181 ANFSEPEIKL AQNVTGNSGI NLTCTSKQGH PKPKKMYFLI TNSTNEYGDN MQISQDNVTE 241 LFSISNSLSL SFPDGVWHMT VVCVLETESM KISSKPLNFT QEFPSPQTYW KEITASVTVA 301 LLLVMLLIIV CHKKPNQPSR PSNTASKLER DSNADRETIN LKELEPQIAS AKPNAE*
Amino acid sequence in FASTA format (without gap)
B7A2*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN
- HGNC:
External links
Nomenclature
Genome databases
Sequence database
Created: 23/05/2007
Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT