
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Homo sapiens B7H1
Citing IMGT RPI entry for B7H1
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens B7H1
- IMGT gene definition: CD274 antigen
Chromosomal localization
- Chromosome: 9
- Chromosomal localization: 9p24
Gene exon/intron organization
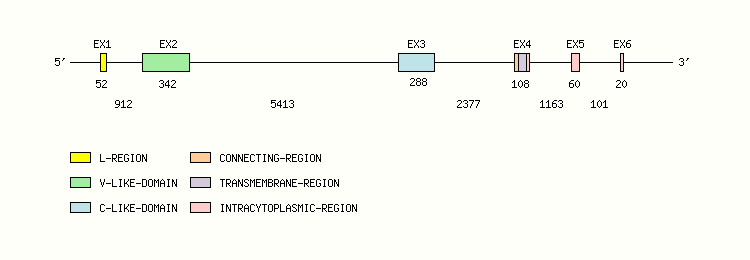
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 2
IMGT reference alleles
| Allele names | Gene functionality | Clone name | IMGT reference sequences | ||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||
| B7H1*01 | F | RP11-57411 | EX1-6 | AL162253 | gDNA |
| B7H1*02 | F | EX1-2 | DQ836393 | cDNA partial (1) | |
IMGT reference sequences (in FASTA format) for the allele(s): B7H1*01 to B7H1*02
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | Clone name | IMGT reference sequences | ||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||
| B7H1*01 | F | EX1-6 | AF177937[1] | cDNA splicing A | |
| EX1-6 | AF233516 | ||||
| EX1-6 | AY254342 | ||||
| MGC:96999 | EX1-6 | BC069381 | |||
| MGC:103912 | EX1-6 | BC074984 | |||
| MGC:142294 | EX1-6 | BC113734 | |||
| MGC:142296 | EX1-6 | BC113736 | |||
| EX2-6 | AK001894 | splicing A partial EX1, EX2 | |||
| EX1, 3-6 | DQ286582 | cDNA (2) splicing B | |||
| EX1, 3-6 | AY291313 | ||||
| EX1-3 | AY714881 | cDNA splicing C (3) | |||
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| B7H1*01 | AF177937 | Tr:Q9NZQ7 | 290 aa | 1 |
| NM_014143 | NP_054862 | 290 aa | 1 | |
| AY291313 | Tr:Q9NZQ7-2 | 176 aa | 2 | |
| AY714881 | Tr:Q9NZQ7-3 | 178 aa | 3 | |
| B7H1*02 | DQ836393 | 126 aa | 1 | |
IMGT notes:
- (1) Partial sequence (126 aa). No EX3-6. In EX2 [D1] a305>t; Y102F, positions according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN.
- (2) Splicing B (176 aa). No EX2 [D1].
- (3) Splicing C (178 aa). EX3 [D2] has two internal splice sites.
IMGT references:
- [1] Dong H. et al. Nat. Med. 5, 1365-1369 (1999). PMID:10581077
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
B7H1*01: AL162253(g)
Nucleotide sequence
1 atgaggatat ttgctgtctt tatattcatg acctactggc atttgctgaa cgcatttact 61 gtcacggttc ccaaggacct atatgtggta gagtatggta gcaatatgac aattgaatgc 121 aaattcccag tagaaaaaca attagacctg gctgcactaa ttgtctattg ggaaatggag 181 gataagaaca ttattcaatt tgtgcatgga gaggaagacc tgaaggttca gcatagtagc 241 tacagacaga gggcccggct gttgaaggac cagctctccc tgggaaatgc tgcacttcag 301 atcacagatg tgaaattgca ggatgcaggg gtgtaccgct gcatgatcag ctatggtggt 361 gccgactaca agcgaattac tgtgaaagtc aatgccccat acaacaaaat caaccaaaga 421 attttggttg tggatccagt cacctctgaa catgaactga catgtcaggc tgagggctac 481 cccaaggccg aagtcatctg gacaagcagt gaccatcaag tcctgagtgg taagaccacc 541 accaccaatt ccaagagaga ggagaagctt ttcaatgtga ccagcacact gagaatcaac 601 acaacaacta atgagatttt ctactgcact tttaggagat tagatcctga ggaaaaccat 661 acagctgaat tggtcatccc agaactacct ctggcacatc ctccaaatga aaggactcac 721 ttggtaattc tgggagccat cttattatgc cttggtgtag cactgacatt catcttccgt 781 ttaagaaaag ggagaatgat ggatgtgaaa aaatgtggca tccaagatac aaactcaaag 841 aagcaaagtg atacacattt ggaggagacg taa
Nucleotide sequence in FASTA format (without gaps)
B7H1*01
Amino acid sequence
1 MRIFAVFIFM TYWHLLNAFT VTVPKDLYVV EYGSNMTIEC KFPVEKQLDL AALIVYWEME 61 DKNIIQFVHG EEDLKVQHSS YRQRARLLKD QLSLGNAALQ ITDVKLQDAG VYRCMISYGG 121 ADYKRITVKV NAPYNKINQR ILVVDPVTSE HELTCQAEGY PKAEVIWTSS DHQVLSGKTT 181 TTNSKREEKL FNVTSTLRIN TTTNEIFYCT FRRLDPEENH TAELVIPELP LAHPPNERTH 241 LVILGAILLC LGVALTFIFR LRKGRMMDVK KCGIQDTNSK KQSDTHLEET *
Amino acid sequence in FASTA format (without gap)
B7H1*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN
- HGNC: 17635
External links
Nomenclature
Genome databases
Sequence database
Created: 23/05/2007
Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT