
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Homo sapiens B7H2
Citing IMGT RPI entry for B7H2
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens B7H2
- IMGT gene definition: inducible T-cell co-stimulator ligand
Chromosomal localization
- Chromosome: 21
- Chromosomal localization: 21q22.3
Gene exon/intron organization
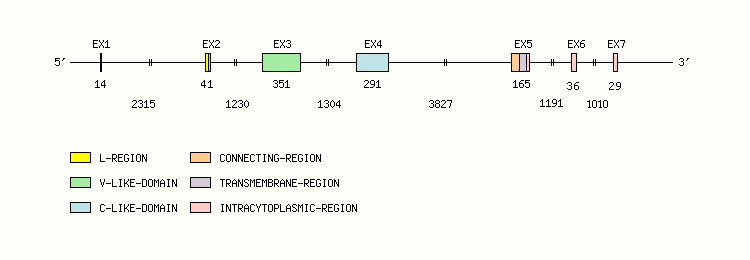
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 1
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| B7H2*01 | F | EX1-7 | AF199028[1] | cDNA |
IMGT reference sequences (in FASTA format) for the allele(s): B7H2*01
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | Clone name | IMGT reference sequences | ||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||
| B7H2*01 | F | EX1-6,8 | AF216749 | cDNA (1) splicing B | |
| EX1-6,8 | AF289028 | ||||
| MGC:70380 | EX1-6,8 | BC064637 | |||
| EX1-6,8 | NM_015259 | ||||
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| B7H2*01 | AF199028 | 309 aa | 1 | |
| AF216749 | O75144 | 302 aa | 2 | |
| NM_015259 | NP_056074 | 302 aa | 2 | |
IMGT notes:
- (1) Splicing B (302 aa). No EX7, utlize a new exon (EX8) of 11 nt.
IMGT references:
- [1] Ling V. et al. J. Immunol. 164, 1653-1657 (2000). PMID:10657606
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
B7H2*01: AF199028(c)
Nucleotide sequence
1 atgcggctgg gcagtcctgg actgctcttc ctgctcttca gcagccttcg agctgatact 61 caggagaagg aagtcagagc gatggtaggc agcgacgtgg agctcagctg cgcttgccct 121 gaaggaagcc gttttgattt aaatgatgtt tacgtatatt ggcaaaccag tgagtcgaaa 181 accgtggtga cctaccacat cccacagaac agctccttgg aaaacgtgga cagccgctac 241 cggaaccgag ccctgatgtc accggccggc atgctgcggg gcgacttctc cctgcgcttg 301 ttcaacgtca ccccccagga cgagcagaag tttcactgcc tggtgttgag ccaatccctg 361 ggattccagg aggttttgag cgttgaggtt acactgcatg tggcagcaaa cttcagcgtg 421 cccgtcgtca gcgcccccca cagcccctcc caggatgagc tcaccttcac gtgtacatcc 481 ataaacggct accccaggcc caacgtgtac tggatcaata agacggacaa cagcctgctg 541 gaccaggctc tgcagaatga caccgtcttc ttgaacatgc ggggcttgta tgacgtggtc 601 agcgtgctga ggatcgcacg gacccccagc gtgaacattg gctgctgcat agagaacgtg 661 cttctgcagc agaacctgac tgtcggcagc cagacaggaa atgacatcgg agagagagac 721 aagatcacag agaatccagt cagtaccggc gagaaaaacg cggccacgtg gagcatcctg 781 gctgtcctgt gcctgcttgt ggtcgtggcg gtggccatag gctgggtgtg cagggaccga 841 tgcctccaac acagctatgc aggtgcctgg gctgtgagtc cggagacaga gctcactgaa 901 tcctggaacc tgctccttct gctctcgtga
Nucleotide sequence in FASTA format (without gaps)
B7H2*01
Amino acid sequence
1 MRLGSPGLLF LLFSSLRADT QEKEVRAMVG SDVELSCACP EGSRFDLNDV YVYWQTSESK 61 TVVTYHIPQN SSLENVDSRY RNRALMSPAG MLRGDFSLRL FNVTPQDEQK FHCLVLSQSL 121 GFQEVLSVEV TLHVAANFSV PVVSAPHSPS QDELTFTCTS INGYPRPNVY WINKTDNSLL 181 DQALQNDTVF LNMRGLYDVV SVLRIARTPS VNIGCCIENV LLQQNLTVGS QTGNDIGERD 241 KITENPVSTG EKNAATWSIL AVLCLLVVVA VAIGWVCRDR CLQHSYAGAW AVSPETELTE 301 SWNLLLLLS*
Amino acid sequence in FASTA format (without gap)
B7H2*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN
- HGNC: 17087
External links
Nomenclature
Genome databases
Sequence database
Created: 23/05/2007
Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT