
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Homo sapiens B7H4
Citing IMGT RPI entry for B7H4
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens B7H4
- IMGT gene definition: V-set domain containing T cell activation inhibitor 1
Chromosomal localization
- Chromosome: 1
- Chromosomal localization: 1p 13.1
Gene exon/intron organization
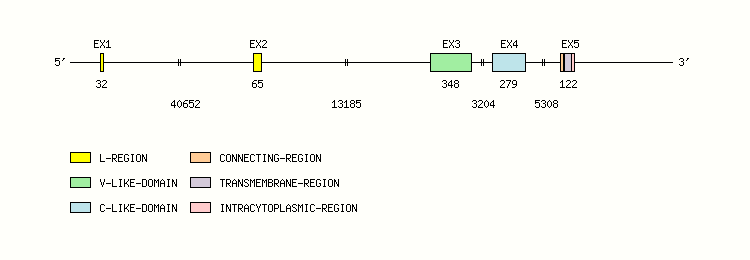
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 2
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| B7H4*01 | F | EX1-5 | AY346100 [1] | cDNA |
| B7H4*02 | F | EX1-5 | AL391476 | gDNA (1) |
IMGT reference sequences (in FASTA format) for the allele(s): B7H4*01 to B7H4*02
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| B7H4*01 | F | EX1-5 | AK026071 | cDNA |
| AY280972 | cDNA | |||
| AY358352 | cDNA | |||
| BC074729 | cDNA | |||
| NM_024626 | cDNA | |||
| EX1-2,4-5 | DQ103757 | cDNA splicing B (2) | ||
| EX1-3 | AY442303 | cDNA splicing C (3) | ||
Corresponding protein database accession numbers
| Allele name | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| B7H4*01 | AY346100 | Tr:Q7Z7D3 | 282 aa | 1 |
| NM_024626 | NP_005182 | 282 aa | 1 | |
| DQ103757 | Tr:Q45VN0 | 166 aa | 2 | |
| AY442303 | Tr:Q5WPZ3 | 87 aa | 3 | |
| B7H4*02 | AL391476 | 282 aa | 1 | |
IMGT notes:
- (1) In EX3 [D1], a62>t; Q21>L, positions according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN.
- (2) Splcing B (166 aa). No EX3.
- (3) Splcing C (87 aa). EX3 [D1] use an alternative splice site 88 nt upstream to the usual 5' ACCEPTOR-SPLICE site. This lead to premature termination.
IMGT references:
- [1] Zang X. and Allison J.P. Proc. Natl. Acad. Sci. U.S.A. 100, 10388-10392 (2003). PMID:12920180
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
B7H4*01: AY346100(c) AL391476(g)
Nucleotide sequence
1 atggcttccc tggggcagat cctcttctgg agcataatta gcatcatcat tattctggct 61 ggagcaattg cactcatcat tggctttggt atttcaggga gacactccat cacagtcact 121 actgtcgcct cagctgggaa cattggggag gatggaatcc agagctgcac ttttgaacct 181 gacatcaaac tttctgatat cgtgatacaa tggctgaagg aaggtgtttt aggcttggtc 241 catgagttca aagaaggcaa agatgagctg tcggagcagg atgaaatgtt cagaggccgg 301 acagcagtgt ttgctgatca agtgatagtt ggcaatgcct ctttgcggct gaaaaacgtg 361 caactcacag atgctggcac ctacaaatgt tatatcatca cttctaaagg caaggggaat 421 gctaaccttg agtataaaac tggagccttc agcatgccgg aagtgaatgt ggactataat 481 gccagctcag agaccttgcg gtgtgaggct ccccgatggt tcccccagcc cacagtggtc 541 tgggcatccc aagttgacca gggagccaac ttctcggaag tctccaatac cagctttgag 601 ctgaactctg agaatgtgac catgaaggtt gtgtctgtgc tctacaatgt tacgatcaac 661 aacacatact cctgtatgat tgaaaatgac attgccaaag caacagggga tatcaaagtg 721 acagaatcgg agatcaaaag gcggagtcac ctacagctgc taaactcaaa ggcttctctg 781 tgtgtctctt ctttctttgc catcagctgg gcacttctgc ctctcagccc ttacctgatg 841 ctaaaataa
Nucleotide sequence in FASTA format (without gaps)
B7H4*01
Amino acid sequence
1 MASLGQILFW SIISIIIILA GAIALIIGFG ISGRHSITVT TVASAGNIGE DGIQSCTFEP 61 DIKLSDIVIQ WLKEGVLGLV HEFKEGKDEL SEQDEMFRGR TAVFADQVIV GNASLRLKNV 121 QLTDAGTYKC YIITSKGKGN ANLEYKTGAF SMPEVNVDYN ASSETLRCEA PRWFPQPTVV 181 WASQVDQGAN FSEVSNTSFE LNSENVTMKV VSVLYNVTIN NTYSCMIEND IAKATGDIKV 241 TESEIKRRSH LQLLNSKASL CVSSFFAISW ALLPLSPYLM LK*
Amino acid sequence in FASTA format (without gap)
B7H4*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN
- HGNC: 28873
- Entrez Gene: 79679
- GENATLAS:
- GeneCards: GC01M117399
- GDB: 11523428
- OMIM: 608162
External links
Nomenclature
Genome databases
Sequence databases
Created: 23/05/2007
Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT