
IMGT Repertoire (RPI)
Other IgSF entries
- Homo sapiens: BTLA
IMGT RPI entry from gene to protein for Mus musculus BTLA
Citing IMGT RPI entry for BTLA
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Mus musculus BTLA
- IMGT gene definition: B and T lymphocyte associated
Chromosomal localization
- Chromosome: 16
- Chromosomal localization: 16B5
Gene exon/intron organization
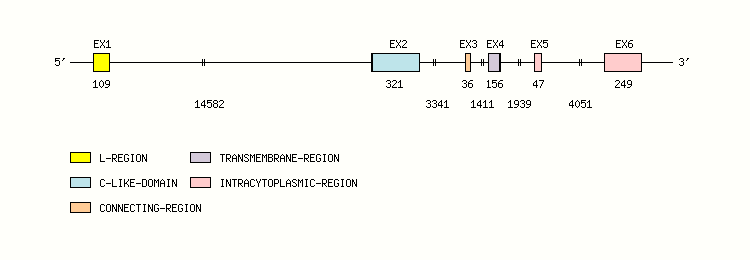
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 4
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | |||
|---|---|---|---|---|---|
| Clones | Exons | Accession numbers | Molecule type | ||
| BTLA*01 | F | EX1-6 | AY293285 | cDNA | |
| BTLA*02 | F | MGC:124218 | EX1-6 | BC108964 | cDNA(1) |
| BTLA*03 | F | MGC:124217 | EX1-6 | BC108963 | cDNA(2) |
| BTLA*04 | F | A630002H24 | EX1-6 | AK041334 | cDNA(3) |
IMGT reference sequences (in FASTA format) for the allele(s): BTLA*01 to BTLA*04
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | |||
|---|---|---|---|---|---|
| Clones | Exons | Accession numbers | Molecule type | ||
| BTLA*01 | F | EX1-6 | NM_001037719 | cDNA | |
| BTLA*02 | F | MGC:155495 | EX1-6 | NM_177584 | cDNA |
Corresponding protein database accession numbers
| BTLA | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide Databases | Protein Databases | |||
| BTLA*01 | AY293285 | Q7TSA3 | 306 aa | 1 |
| BTLA*02 | BC108964 | 306 aa | 1 | |
| BTLA*03 | BC108963 | 305 aa | 2 | |
| BTLA*04 | AK041334 | 305 aa | 2 | |
IMGT notes:
- (1) Splicing B lacks the first codon EX4 while preserving the reading frame.
- (2) In EX2, a118>c; N40>H numbering according to IMGT unique numbering for C-DOMAIN and C-LIKE-DOMAIN.
- (3) In EX4, g54>a51; E19>18.
- (4) mutations are many.
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
BTLA*01: AY293285(c)
Nucleotide sequence
1 atgaagacag tgcctgccat gcttgggact cctcggttat ttagggaatt cttcatcctc 61 catctgggcc tctggagcat cctttgtgag aaagctacta agaggaatga tgaagagtgt 121 gaagtgcaac ttaatattaa gaggaattcc aaacactctg cctggacagg agagttattt 181 aaaattgaat gtcctgtgaa atactgtgtt catagaccta atgtgacttg gtgtaagcac 241 aatggaacaa tctgggtacc ccttgaagtt ggtcctcagc tatacactag ttgggaagaa 301 aatcgatcag ttccggtttt tgttctccat tttaaaccaa tacatctcag tgataacggg 361 tcgtatagct gttctacaaa cttcaattct caagttatta atagccattc agtaaccatc 421 catgtgagag aaaggactca aaactcttca gaacacccac taataacagt atctgacatc 481 ccagatgcca ccaatgcctc aggaccatcc accatggaag agaggccagg caggacttgg 541 ctgctttaca ccttgcttcc tttgggggca ttgcttctgc tccttgcctg tgtctgcctg 601 ctctgctttc tgaaaaggat ccaagggaaa gaaaagaagc cttctgactt ggcaggaagg 661 gacactaacc tggttgatat tccagccagt tccaggacaa atcaccaagc actgccatca 721 ggaactggaa tttatgataa tgatccctgg tctagcatgc aggatgaatc tgaattgaca 781 attagcttgc aatcagagag aaacaaccag ggcattgttt atgcttcttt gaaccattgt 841 gttattggaa ggaatccaag acaggaaaac aacatgcagg aggcacccac agaatatgca 901 tccatttgtg tgagaagtta a
Nucleotide sequence in FASTA format (without gaps)
BTLA*01
Amino acid sequence
1 MKTVPAMLGT PRLFREFFIL HLGLWSILCE KATKRNDEEC EVQLNIKRNS KHSAWTGELF 61 KIECPVKYCV HRPNVTWCKH NGTIWVPLEV GPQLYTSWEE NRSVPVFVLH FKPIHLSDNG 121 SYSCSTNFNS QVINSHSVTI HVRERTQNSS EHPLITVSDI PDATNASGPS TMEERPGRTW 181 LLYTLLPLGA LLLLLACVCL LCFLKRIQGK EKKPSDLAGR DTNLVDIPAS SRTNHQALPS 241 GTGIYDNDPW SSMQDESELT ISLQSERNNQ GIVYASLNHC VIGRNPRQEN NMQEAPTEYA 301 SICVRS*
Amino acid sequence in FASTA format (without gap)
BTLA*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays: C-LIKE-DOMAINs
- IMGT Collier de perles: C-LIKE-DOMAIN
IMGT databases
- IMGT/3Dstructure-DB: 1xau
External links
Genome databases
- Entrez Gene: 208154
- GENATLAS:
- GeneCards:
- GDB:
- OMIM:
Sequence databases
Created: 24/11/2006
Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT