
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Homo sapiens CD2
Citing IMGT RPI entry for CD2
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens CD2
- IMGT gene definition: CD2 molecule
Chromosomal localization
- Chromosome: 1
- Chromosomal localization: 1p13
Gene exon/intron organization
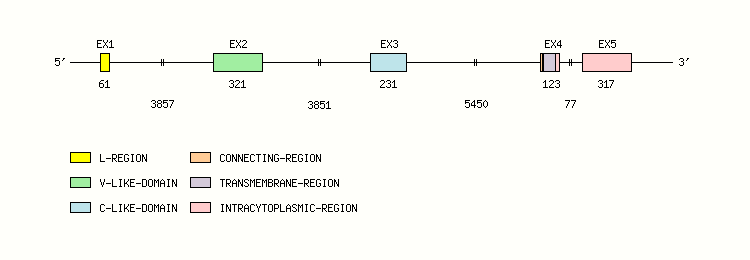
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 4
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| CD2*01 | F | EX1-5 | X07871 [1] | gDNA |
| CD2*02 | F | EX1-5 | M16445 [2] | cDNA (1) |
| CD2*03 | F | EX1-5 | M16336 [3] | cDNA (2) |
| CD2*04 | F | EX1-5 | AK223393 | cDNA (3) |
IMGT reference sequences (in FASTA format) for the allele(s): CD2*01 to CD2*04
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| CD2*01 | F | EX1-5 | M19806 | gDNA |
| AL135798 | gDNA | |||
| M14362 | cDNA | |||
| CD2*02 | F | EX1-5 | BC033583 | cDNA |
| NM_001767 | cDNA | |||
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| CD2*01 | X07871 | P06729 | 351 aa | 1 |
| CD2*02 | M16445 | 351 aa | 1 | |
| NM_001767 | NP_001758 | 351 aa | 1 | |
| CD2*03 | M16336 | 360 aa | 1 | |
| CD2*04 | AK223393 | Tr:Q53F96 | 351 aa | 1 |
IMGT notes:
- (1) In EX5 62c>a 21H>Q.
- (2) 360 aa. In EX5, c276 is absent. This deletion in the ORF leads to frame shift and the translation continues 27 nt beyond the 3' DONOR-SPLICE site until the first STOP-CODON, in frame, in the down stream intron.
- (3) In EX3 [D2] a117>g, positions according to IMGT unique numbering for C-DOMAIN and C-LIKE-DOMAIN.
IMGT references:
- [1] Lang G. et al, EMBO J. 7, 1675-1682 (1988). PMID:2901953
- [2] Seed B. and Aruffo A. Proc. Natl. Acad. Sci. U.S.A. 84, 3365-3369 (1987). PMID:2437578
- [3] Sayre P.H. et al, Proc. Natl. Acad. Sci. U.S.A. 84, 2941-2945 (1987). PMID:2883656
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
CD2*01: X07871(g)
Nucleotide sequence
1 atgagctttc catgtaaatt tgtagccagc ttccttctga ttttcaatgt ttcttccaaa 61 ggtgcagtct ccaaagagat tacgaatgcc ttggaaacct ggggtgcctt gggtcaggac 121 atcaacttgg acattcctag ttttcaaatg agtgatgata ttgacgatat aaaatgggaa 181 aaaacttcag acaagaaaaa gattgcacaa ttcagaaaag agaaagagac tttcaaggaa 241 aaagatacat ataagctatt taaaaatgga actctgaaaa ttaagcatct gaagaccgat 301 gatcaggata tctacaaggt atcaatatat gatacaaaag gaaaaaatgt gttggaaaaa 361 atatttgatt tgaagattca agagagggtc tcaaaaccaa agatctcctg gacttgtatc 421 aacacaaccc tgacctgtga ggtaatgaat ggaactgacc ccgaattaaa cctgtatcaa 481 gatgggaaac atctaaaact ttctcagagg gtcatcacac acaagtggac caccagcctg 541 agtgcaaaat tcaagtgcac agcagggaac aaagtcagca aggaatccag tgtcgagcct 601 gtcagctgtc cagagaaagg tctggacatc tatctcatca ttggcatatg tggaggaggc 661 agcctcttga tggtctttgt ggcactgctc gttttctata tcaccaaaag gaaaaaacag 721 aggagtcgga gaaatgatga ggagctggag acaagagccc acagagtagc tactgaagaa 781 aggggccgga agccccacca aattccagct tcaacccctc agaatccagc aacttcccaa 841 catcctcctc caccacctgg tcatcgttcc caggcaccta gtcatcgtcc cccgcctcct 901 ggacaccgtg ttcagcacca gcctcagaag aggcctcctg ctccgtcggg cacacaagtt 961 caccagcaga aaggcccgcc cctccccaga cctcgagttc agccaaaacc tccccatggg 1021 gcagcagaaa actcattgtc cccttcctct aattaa
Nucleotide sequence in FASTA format (without gaps)
CD2*01
Amino acid sequence
1 MSFPCKFVAS FLLIFNVSSK GAVSKEITNA LETWGALGQD INLDIPSFQM SDDIDDIKWE 61 KTSDKKKIAQ FRKEKETFKE KDTYKLFKNG TLKIKHLKTD DQDIYKVSIY DTKGKNVLEK 121 IFDLKIQERV SKPKISWTCI NTTLTCEVMN GTDPELNLYQ DGKHLKLSQR VITHKWTTSL 181 SAKFKCTAGN KVSKESSVEP VSCPEKGLDI YLIIGICGGG SLLMVFVALL VFYITKRKKQ 241 RSRRNDEELE TRAHRVATEE RGRKPHQIPA STPQNPATSQ HPPPPPGHRS QAPSHRPPPP 301 GHRVQHQPQK RPPAPSGTQV HQQKGPPLPR PRVQPKPPHG AAENSLSPSS N*
Amino acid sequence in FASTA format (without gap)
CD2*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN
- IMGT/3Dstructure-DB: 1cdb
- HGNC: 1639
- Entrez Gene: 914
- GENATLAS: 79
- GeneCards: GC01P117009
- GDB: 118735
- OMIM: 186990
IMGT databases
External links
Nomenclature
Genome databases
Sequence database
Created: 23/05/2007
Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT