
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Homo sapiens CD48
Citing IMGT RPI entry for CD48
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens CD48
- IMGT gene definition: CD48 molecule
Chromosomal localization
- Chromosome: 1
- Chromosomal localization: 1q21.3-q22
Gene exon/intron organization
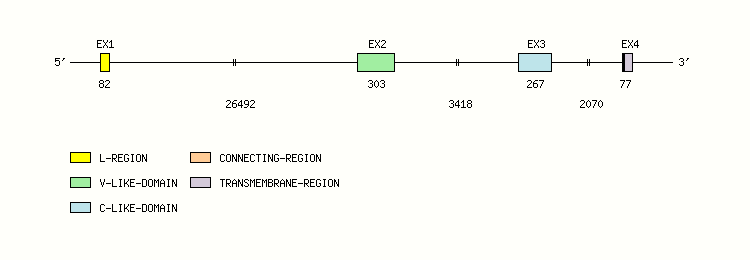
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 7
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| CD48*01 | F | EX1-4 | M37766 [1] | cDNA |
| CD48*02 | F | EX1-4 | AL121985 | gDNA (1) |
| CD48*03 | F | EX1-4 | M59904 [2] | cDNA (2) |
| CD48*04 | F | EX1-4 | X06341[3] | cDNA (3) |
| CD48*05 | F | EX1-4 | BC016182 | cDNA (4) |
| CD48*06 | F | EX1-4 | CR457012 | cDNA (5) |
| CD48*07 | F | EX1-4 | BT019813 | cDNA (6) |
IMGT reference sequences (in FASTA format) for the allele(s): CD48*01 to CD48*07
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| CD48*02 | F | EX1-4 | BC030224 | cDNA splicing B (7) |
| CD48*05 | F | EX1-4 | NM_001778 | cDNA |
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| CD48*01 | M37766 | P09326 | 243 aa | 1 |
| CD48*02 | AL121985 | 243 aa | 1 | |
| CD48*03 | M59904 | 243 aa | 1 | |
| CD48*04 | X06341 | 243 aa | 1 | |
| CD48*05 | BC016182 | 243 aa | 1 | |
| NM_001778 | NP_001769 | 243 aa | 1 | |
| CD48*06 | CR457012 | Tr:Q6IAZ2 | 243 aa | 1 |
| CD48*07 | BT019813 | Tr:Q5U055 | 243 aa | 1 |
IMGT notes:
- (1) In EX2 [D1] a159>t; N53>I, positions according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN
- (2) In EX1 c6>g; C2>W, EX2 [D1] a159>t; N53>I, positions according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN and in EX3 [D2] g361>c, positions according to IMGT unique numbering for C-DOMAIN and C-LIKE-DOMAIN
- (3) In EX2 [D1] a159>t; N53>I, positions according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN and in EX3 [D2] g361>c, positions according to IMGT unique numbering for C-DOMAIN and C-LIKE-DOMAIN
- (4) In EX2 [D1] a159>t; N53>I, positions according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN and in EX3 [D2] c55>t; positions according to IMGT unique numbering for C-DOMAIN and C-LIKE-DOMAIN
- (5) In EX2 [D1] a159>t; N53>I, positions according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN and in EX3 [D2] t134.3>c, positions according to IMGT unique numbering for C-DOMAIN and C-LIKE-DOMAIN
- (6) In EX2 [D1] a159>t; N53>I and c262>t, positions according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN
- (7) Splicing B. In EX2 [D1] a159>t; N53>I, positions according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN. No EX3-4. EX2 has no DONOR-SPLICE site and as a consequence the translation continues beyond the usual splice site until the first STOP-CODON, in frame, in the down stream intron.
IMGT references:
- [1] Korinek V. et al, Immunogenetics 33:108-112(1991). PMID:1999350
- [2] Vaughan H.A. et al., Immunogenetics 33:113-117(1991). PMID:1999351
- [3] Staunton D.E. and Thorley-Lawson D.A., EMBO J. 6:3695-3701(1987). PMID:2828034
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
CD48*01: AL121985(g) M37766(c)
Nucleotide sequence
1 atgtgctcca gaggttggga ttcgtgtctg gctctggaat tgctactgct gcctctgtca 61 ctcctggtga ccagcattca aggtcacttg gtacatatga ccgtggtctc cggcagcaac 121 gtgactctga acatctctga gagcctgcct gagaactaca aacaactaac ctggttttat 181 actttcgacc agaagaatgt agaatgggat tccagaaaat ctaagtactt tgaatccaaa 241 tttaaaggca gggtcagact tgatcctcag agtggcgcac tgtacatctc taaggtccag 301 aaagaggaca acagcaccta catcatgagg gtgttgaaaa agactgggaa tgagcaagaa 361 tggaagatca agctgcaagt gcttgaccct gtacccaagc ctgtcatcaa aattgagaag 421 atagaagaca tggatgacaa ctgttatctg aaactgtcat gtgtgatacc tggcgagtct 481 gtaaactaca cctggtatgg ggacaaaagg cccttcccaa aggagctcca gaacagtgtg 541 cttgaaacca cccttatgcc acataattac tccaggtgtt atacttgcca agtcagcaat 601 tctgtgagca gcaagaatgg cacggtctgc ctcagtccac cctgtaccct ggcccggtcc 661 tttggagtag aatggattgc aagttggcta gtggtcacgg tgcccaccat tcttggcctg 721 ttacttacct ga
Nucleotide sequence in FASTA format (without gaps)
CD48*01
Amino acid sequence
1 MCSRGWDSCL ALELLLLPLS LLVTSIQGHL VHMTVVSGSN VTLNISESLP ENYKQLTWFY 61 TFDQKNVEWD SRKSKYFESK FKGRVRLDPQ SGALYISKVQ KEDNSTYIMR VLKKTGNEQE 121 WKIKLQVLDP VPKPVIKIEK IEDMDDNCYL KLSCVIPGES VNYTWYGDKR PFPKELQNSV 181 LETTLMPHNY SRCYTCQVSN SVSSKNGTVC LSPPCTLARS FGVEWIASWL VVTVPTILGL 241 LLT*
Amino acid sequence in FASTA format (without gap)
CD48*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN
- IMGT/3Dstructure-DB: 2dru
IMGT databases
External links
Nomenclature
- HGNC: 1683
Genome databases
- Entrez Gene: 962
- GENATLAS: 375
- GeneCards: GC01M158915
- GDB: 119725
- OMIM: 109530
Sequence databases
Created: 23/05/2007
Last updated: 02/10/2025 15:10
Authors: Sanja Perkovska, Phani vijay and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Sanja Perkovska, Phani vijay and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT