
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Mus musculus CD48
Citing IMGT RPI entry for CD48
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Mus musculus CD48
- IMGT gene definition: CD48 antigen
Chromosomal localization
- Chromosome: 1
- Chromosomal localization: 1H3;1 93.3 cM
Gene exon/intron organization
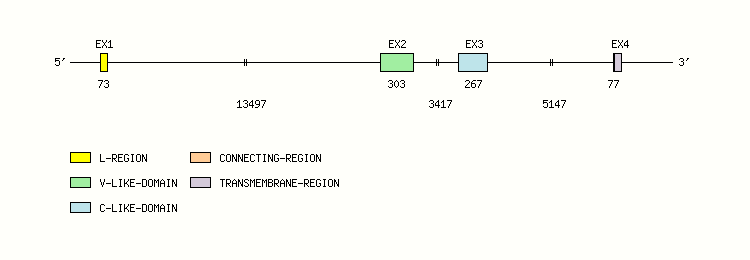
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 5
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | |||
|---|---|---|---|---|---|
| Exons | Strain | Accession numbers | Molecule type | ||
| CD48*01 | F | EX1-4 | C57BL/6J | AK007741 | cDNA |
| CD48*02 | F | EX1-4 | BC060977 | cDNA (1) | |
| CD48*03 | F | EX1-4 | NZB/B1NJ | AB196821 | cDNA (2) |
| CD48*04 | F | EX1-4 | BALB/c | AK146173 | cDNA (3) |
| CD48*05 | F | EX1-2, 4 | NOD | AK088027 | cDNA (4) splicing B |
IMGT reference sequences (in FASTA format) for the allele(s): CD48*01 to CD48*05
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | |||
|---|---|---|---|---|---|
| Exons | Strain | Accession numbers | Molecule type | ||
| CD48*01 | F | EX1-4 | C57BL/6J | AK084984 | cDNA |
| C57BL/6J | AK151601 | ||||
| BALB/c | X17501 | ||||
| BALB/c | X53526 | ||||
| MRL/MpJ | AB196820 | ||||
| NM_007649 | |||||
| CD48*03 | F | EX1-4 | NZW/LacJ | AB196822 | cDNA |
| BXSB/MpJ | AB196823 | ||||
Corresponding protein database accession numbers
| CD48*01 | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| CD48*01 | AK007741 | P18181, Q545K2 | 240 aa | 1 |
| NM_007649 | NP_031675 | 240 aa | 1 | |
| CD48*02 | BC060977 | Q6P905 | 240 aa | 1 |
| CD48*03 | AB196821 | 240 aa | 1 | |
| CD48*04 | AK146173 | 240 aa | 1 | |
| CD48*05 | AK088027 | Tr:Q8C2T1 | 151 aa | 2 |
IMGT notes:
- (1) In EX1 14a>g; 5K>R.
- (2) In EX2[D1] 253a>g; 85G>D, according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN.
- (3) In EX1 14a>g; 5K>R, In EX2[D1] 80c>a; 27P>Q and 253a>g; 85G>D, according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN .
- (4) Splicing B. In EX1 14a>g; 5K>R and in EX2[D1] 253a>g; 85G>D, according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN. No EX3.
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
CD48*01: AK007741(c)
Nucleotide sequence
1 atgtgcttca taaaacaggg atggtgtctg gtcctggaac tgctactgct gcccttggga 61 actggatttc aaggtcattc aataccagat ataaatgcca ccaccggcag caatgtaacc 121 ctgaaaatcc ataaggaccc acttggacca tataaacgta tcacctggct tcatactaaa 181 aatcagaaga ttttagagta caactataat agtacaaaga caatcttcga gtctgaattt 241 aaaggcaggg tttatcttga agaaaacaat ggtgcacttc atatctctaa tgtccggaaa 301 gaggacaaag gtacctacta catgagagtg ctgcgtgaaa ctgagaacga gttgaagata 361 accctggaag tatttgatcc tgtgcccaag ccttccatag aaatcaataa gactgaagcg 421 tcgactgatt cctgtcacct gaggctatcg tgtgaggtaa aggaccagca tgttgactat 481 acttggtatg agagctcggg acctttcccc aaaaagagtc caggatatgt gctcgatctc 541 atcgtcacac cacagaacaa gtctacattt tacacctgcc aagtcagcaa tcctgtaagc 601 agcaagaacg acacagtgta cttcactcta ccttgtgatc tagccagatc ttctggagta 661 tgttggactg caacttggct agtggtcaca acactcatca ttcacaggat cctgttaacc 721 tga
Nucleotide sequence in FASTA format (without gaps)
CD48*01
Amino acid sequence
1 MCFIKQGWCL VLELLLLPLG TGFQGHSIPD INATTGSNVT LKIHKDPLGP YKRITWLHTK 61 NQKILEYNYN STKTIFESEF KGRVYLEENN GALHISNVRK EDKGTYYMRV LRETENELKI 121 TLEVFDPVPK PSIEINKTEA STDSCHLRLS CEVKDQHVDY TWYESSGPFP KKSPGYVLDL 181 IVTPQNKSTF YTCQVSNPVS SKNDTVYFTL PCDLARSSGV CWTATWLVVT TLIIHRILLT 241 *
Amino acid sequence in FASTA format (without gap)
CD48*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT RepertoireChromosomal localization
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN
- HGNC:
External links
Nomenclature
Genome databases
Sequence databases
Created: 23/05/2007
Last updated: 02/10/2025 15:10
Authors: Phani vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Phani vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT