
IMGT Repertoire (RPI)
Other CD7 entries
- Mus musculus: CD7
IMGT RPI entry from gene to protein for Homo sapiens CD7
Citing IMGT RPI entry for CD7
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens CD7
- IMGT gene definition: CD7 molecule
Chromosomal localization
- Chromosome: 17
- Chromosomal localization: 17q25, 2-q25,3
Gene exon/intron organization
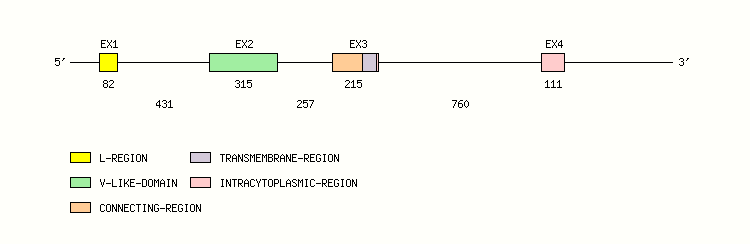
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 5
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| CD7*01 | F | EX1-4 | M37271 [1] | gDNA |
| CD7*02 | F | EX1-4 | AY935536 | cDNA (1) |
| CD7*03 | F | EX1-4 | AK223465 [2] | cDNA (2) |
| CD7*04 | F | EX1-4 | AY935534 | cDNA (3) |
| CD7*05 | F | EX1-4 | AY935535 | cDNA (4) |
IMGT reference sequences (in FASTA format) for the allele(s): CD7*01 to CD7*05
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | |||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | Partiality | ||
| CD7*01 | F | EX1-4 | AC132872 (28474..31208) | gDNA | |
| D00749 | gDNA | ||||
| BC009293 | cDNA | ||||
| BC013297 | cDNA | ||||
| BT006696 | cDNA | ||||
| X06180 | cDNA | ||||
| AY935537 | cDNA (5) | partial | |||
| EX1-2 | BM917451 | cDNA | |||
Corresponding protein database accession numbers
| Allele Name | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| CD7*01 | M37271 | P09564 | 240 aa | 1 |
| NM_006137 | NP_006128 | 240 aa | 1 | |
| AY935537 | Q29VG2 | 236 aa | 1 | |
| CD7*02 | AY935536 | P09564 | 240 aa | 1 |
| CD7*03 | AK223465 | Q53F24 | 240 aa | 1 |
| CD7*04 | AY935534 | 240 aa | 1 | |
| CD7*05 | AY935535 | 240 aa | 1 | |
IMGT notes:
- (1) In EX3 146g>a.
- (2) In EX3 55c>t; 18A>V.
- (3) In EX3 103c>t; 34A>V.
- (4) In EX3 205c>t; 68A>V.
- (5) AY935537 was considered as partial because in EX2, it has twelve deletions.
IMGT references:
- [1] Schanberg L.E. et al, Proc. Natl. Acad. Sci. USA 88, 603-607 (1991). PMID:1703303
- [2] Maruyama K. and Sugano S., Gene 138,171-174 (1994). PMID:8125298
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
CD7*01: M37271(g)
Nucleotide sequence
1 atggccgggc ctccgaggct cctgctgctg cccctgcttc tggcgctggc tcgcggcctg 61 cctggggccc tggctgccca agaggtgcag cagtctcccc actgcacgac tgtccccgtg 121 ggagcctccg tcaacatcac ctgctccacc agcgggggcc tgcgtgggat ctacctgagg 181 cagctcgggc cacagcccca agacatcatt tactacgagg acggggtggt gcccactacg 241 gacagacggt tccggggccg catcgacttc tcagggtccc aggacaacct gactatcacc 301 atgcaccgcc tgcagctgtc ggacactggc acctacacct gccaggccat cacggaggtc 361 aatgtctacg gctccggcac cctggtcctg gtgacagagg aacagtccca aggatggcac 421 agatgctcgg acgccccacc aagggcctct gccctccctg ccccaccgac aggctccgcc 481 ctccctgacc cgcagacagc ctctgccctc cctgacccgc cagcagcctc tgccctccct 541 gcggccctgg cggtgatctc cttcctcctc gggctgggcc tgggggtggc gtgtgtgctg 601 gcgaggacac agataaagaa actgtgctcg tggcgggata agaattcggc ggcatgtgtg 661 gtgtacgagg acatgtcgca cagccgctgc aacacgctgt cctcccccaa ccagtaccag 721 tga
Nucleotide sequence in FASTA format (without gaps)
CD7*01
Amino acid sequence
1 MAGPPRLLLL PLLLALARGL PGALAAQEVQ QSPHCTTVPV GASVNITCST SGGLRGIYLR 61 QLGPQPQDII YYEDGVVPTT DRRFRGRIDF SGSQDNLTIT MHRLQLSDTG TYTCQAITEV 121 NVYGSGTLVL VTEEQSQGWH RCSDAPPRAS ALPAPPTGSA LPDPQTASAL PDPPAASALP 181 AALAVISFLL GLGLGVACVL ARTQIKKLCS WRDKNSAACV VYEDMSHSRC NTLSSPNQYQ 241 *
Amino acid sequence in FASTA format (without gap)
CD7*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN
External links
Nomenclature
- HGNC: 1695
Genome databases
- Entrez Gene: 924
- GENATLAS: CD7
- GeneCards: GC17M077866
- GDB: CD7
- OMIM: 186820
Sequence databases
Created: 20/02/2007
Last updated: 02/10/2025 15:10
Authors: Nelly Rozas, Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Nelly Rozas, Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT