
IMGT Repertoire (RPI)
Other CD7 entries
- Homo sapiens: CD7
IMGT RPI entry from gene to protein for Mus musculus CD7
Citing IMGT RPI entry for CD7
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Mus musculus CD7
- IMGT gene definition: Mus musculus CD7 antigen
Chromosomal localization
- Chromosome: 11
- Chromosomal localization: 11 E2; 11 74.0 cM
Gene exon/intron organization
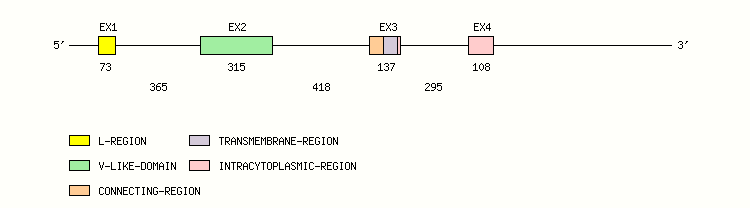
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 3
IMGT reference alleles
| Allele names | Strain | Haplotype | Gene functionality | IMGT reference sequences | Partiality | ||
|---|---|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||||
| CD7*01 | BALB/c | d | F | EX1-4 | D31956 [1] | gDNA | |
| CD7*02 | 129 | bc | F | EX1-4 | U23462 [2] | gDNA (1) | |
| CD7*03 | FVB/N | F | EX1-4 | BC024376 [3] | cDNA (2) | ||
IMGT reference sequences (in FASTA format) for the allele(s): CD7*01 to CD7*03
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Strain | Haplotype | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||||
| CD7*01 | F | EX1-4 | AL662887 (69891..72558) | gDNA | ||
| C57BL/6J | b | F | EX1-4 | AK136444 | cDNA | |
| NOD | F | EX1-4 | AK154339 | cDNA | ||
| (C57BL/6 x CBA)F1 | F | EX1-4 | D10329 | cDNA | ||
| CD7*03 | F | EX1-4 | CT010368 | cDNA | ||
Corresponding protein database accession numbers
| Allele Name | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| CD7*01 | D31956 | P50283 | 210 aa | 1 |
| NM_009854 | NP_033984 | 210 aa | 1 | |
| CD7*02 | U23462 | 210 aa | 1 | |
| CD7*03 | BC024376 | Q8R1M4 | 210 aa | 1 |
IMGT notes:
- (1) In EX2 [D1] 150t>g; 50F>L, numbering according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN.
- (2) In EX2 [D1] 28c>g; 10L>V, 31a>g, 32c>t; 11T>V and 54t>c, numbering according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN. In EX4 33a>c; 11E>D
IMGT references:
- [1] Yoshikawa K.et al, Immunogenetics 37, 114-119 (1993). PMID:7678579
- [2] Lee D.M. et al, Immunogenetics 39, 289-290 (1994). PMID:7509775
- [3] Strausberg R.L et al, Proc. Natl. Acad. Sci. USA 99, 16899-16903 (2002). PMID:12477932
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
CD7*01: D31956(g)
Nucleotide sequence
1 atgactcagc aggcagtgct ggctttgctg cttacactgg ccggaatcct gcctggcccc 61 ctggatgccc aagacgtaca ccagtccccc cgactcacga ttgcctctga gggggattct 121 gtcaacatca cctgctctac aagagggcac ctggaaggga tcttaatgaa gaagatctgg 181 cctcaggctt acaatgtgat ttactttgaa gaccggcagg agcccacagt agacaggacc 241 ttctcaggcc gaattaattt ctctggttcc cagaagaacc tgaccatcac cataagctcc 301 ctccagctgg cagacactgg agactacacc tgcgaggctg tcaggaaagt cagtgcccgt 361 ggcttgttca ccacggttgt ggtgaaagaa aaatcatccc aagaagcata cagatcccag 421 gaacctctgc agacatcatt ttccttccca gctgccattg ctgtaggctt cttcttcacc 481 gggctgctcc ttggggtggt gtgcagcatg ctgaggaaga tacagatcaa gaaactgtgt 541 gcctcaggga ttaaggaatc tccgtgcgta gtgtatgaag acatgtccta cagcaaccgc 601 aagacgccat gcatccccaa ccagtaccag tga
Nucleotide sequence in FASTA format (without gaps)
CD7*01
Amino acid sequence
1 MTQQAVLALL LTLAGILPGP LDAQDVHQSP RLTIASEGDS VNITCSTRGH LEGILMKKIW 61 PQAYNVIYFE DRQEPTVDRT FSGRINFSGS QKNLTITISS LQLADTGDYT CEAVRKVSAR 121 GLFTTVVVKE KSSQEAYRSQ EPLQTSFSFP AAIAVGFFFT GLLLGVVCSM LRKIQIKKLC 181 ASGIKESPCV VYEDMSYSNR KTPCIPNQYQ *
Amino acid sequence in FASTA format (without gap)
CD7*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN
External links
Genome databases
- Entrez Gene: 12516
- GENATLAS:
- GeneCards:
- GDB: CD7
- OMIM:
Sequence databases
Created: 19/02/2007
Last updated: 02/10/2025 15:10
Authors: Nelly Rozas, Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Nelly Rozas, Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT