
IMGT Repertoire (RPI)
Other CD8A entries
- Mus musculus: CD8A
IMGT RPI entry from gene to protein for Homo sapiens CD8A
Citing IMGT RPI entry for CD8A
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens CD8A
- IMGT gene definition: CD8A antigen, alpha polypeptide (p32)
Chromosomal localization
- Chromosome: 2
- Chromosomal localization: 2p12
Gene exon/intron organization
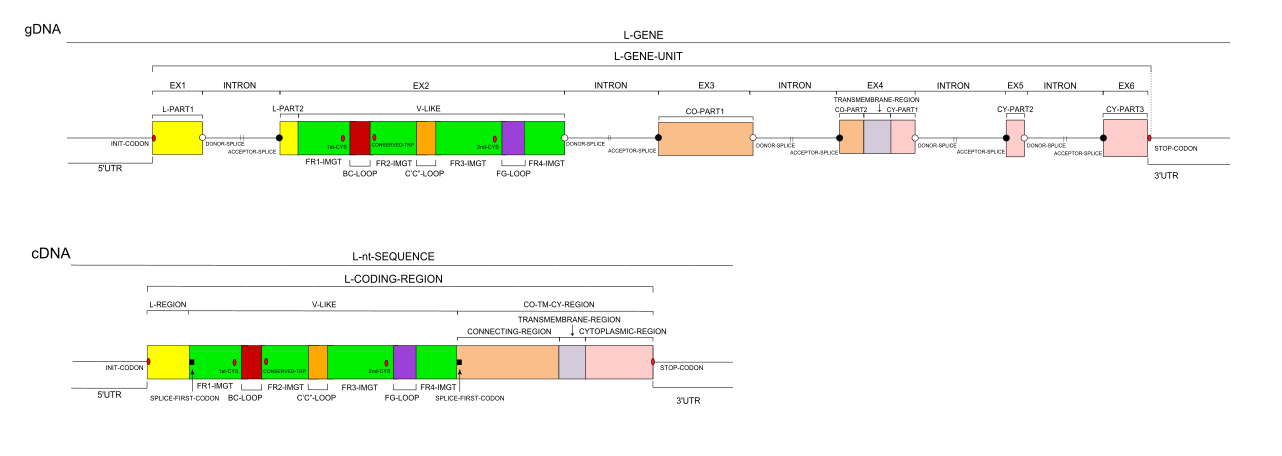
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 4
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| CD8A*01 | F | EX1-6 | M27161 [1] | gDNA |
| CD8A*02 | F | EX1-2 | M26313 [2] | gDNA (1) |
| EX3-4 | M26314 | gDNA (1) | ||
| EX5-6 | M26315 | gDNA (1) | ||
| CD8A*03 | (F) | EX1-6 | AY039664 [3] | cDNA (2) |
| CD8A*04 | (F) | EX1-6 | BC025715 | cDNA (3) |
IMGT reference sequences (in FASTA format) for the allele(s): CD8A*01 to CD8A*04
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| CD8A*01 | F | EX1-6 | AC064848 | gDNA |
| (F) | M12824 | cDNA | ||
| HomSap_1_chr2 | cDNA splicing A | |||
| EX1-3, 5-6 | HomSap_2_chr2 | cDNA (4) splicing B | ||
| CD8A*02 | (F) | EX1-6 | M12828 | cDNA |
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| CD8A*01 | M27161 | P01732 | 235 aa | 1 |
| NM_001768 | NP_001759 | 235 aa | 1 | |
| NM_171827 | NP_001769 | 198 aa | 2 | |
| CD8A*03 | AY039664 | 235 aa | 1 | |
| CD8A*04 | BC025715 | 235 aa | 1 | |
IMGT notes:
- (1) In EX4 c51>t.
- (2) In EX2 [D] a298>c; G100>S, numbering according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN. This mutation prevents CD8 expression.
- (3) In EX2 [D] a302>g; Y101>C, numbering according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN and in EX4 51c>t.
- (4) No EX4 with 198 aa.
IMGT references:
- [1] Nakayama K. et al, Immunogenetics 30, 393-397 (1989). PMID:2509342
- [2] Norment A.M. et al, The Journal of Immunology, 3312-3319 (1989). PMID:2496167
- [3] De la Calle-Martin O. et al, The Journal of clinical investigation. 108, 117-123 (2001). PMID:11435463
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
CD8A*01: M27161(g)
Nucleotide sequence
1 atggccttac cagtgaccgc cttgctcctg ccgctggcct tgctgctcca cgccgccagg 61 ccgagccagt tccgggtgtc gccgctggat cggacctgga acctgggcga gacagtggag 121 ctgaagtgcc aggtgctgct gtccaacccg acgtcgggct gctcgtggct cttccagccg 181 cgcggcgccg ccgccagtcc caccttcctc ctatacctct cccaaaacaa gcccaaggcg 241 gccgaggggc tggacaccca gcggttctcg ggcaagaggt tgggggacac cttcgtcctc 301 accctgagcg acttccgccg agagaacgag ggctactatt tctgctcggc cctgagcaac 361 tccatcatgt acttcagcca cttcgtgccg gtcttcctgc cagcgaagcc caccacgacg 421 ccagcgccgc gaccaccaac accggcgccc accatcgcgt cgcagcccct gtccctgcgc 481 ccagaggcgt gccggccagc ggcggggggc gcagtgcaca cgagggggct ggacttcgcc 541 tgtgatatct acatctgggc gcccctggcc gggacttgtg gggtccttct cctgtcactg 601 gttatcaccc tttactgcaa ccacaggaac cgaagacgtg tttgcaaatg tccccggcct 661 gtggtcaaat cgggagacaa gcccagcctt tcggcgagat acgtctaa
Nucleotide sequence in FASTA format (without gaps)
CD8A*01
Amino acid sequence
1 MALPVTALLL PLALLLHAAR PSQFRVSPLD RTWNLGETVE LKCQVLLSNP TSGCSWLFQP 61 RGAAASPTFL LYLSQNKPKA AEGLDTQRFS GKRLGDTFVL TLSDFRRENE GYYFCSALSN 121 SIMYFSHFVP VFLPAKPTTT PAPRPPTPAP TIASQPLSLR PEACRPAAGG AVHTRGLDFA 181 CDIYIWAPLA GTCGVLLLSL VITLYCNHRN RRRVCKCPRP VVKSGDKPSL SARYV*
Amino acid sequence in FASTA format (without gap)
CD8A*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
- Protein displays: V-LIKE-DOMAINs
- IMGT Collier de perles: V-LIKE
External links
Nomenclature
- HGNC: 1706
Genome databases
- Entrez Gene: 925
- GENATLAS: 3800
- GeneCards: GC02M086923
- OMIM: 186910
Sequence databases
Created: 23/05/2007
Last updated: 02/10/2025 15:10
Authors: Mélissa Cambon, Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Mélissa Cambon, Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT