
IMGT Repertoire (RPI)
Other CD8A entries
- Homo sapiens: CD8A
IMGT RPI entry from gene to protein for Mus musculus CD8A
Citing IMGT RPI entry for CD8A
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Mus musculus CD8A
- IMGT gene definition: CD8A antigen, alpha polypeptide (p32)
Chromosomal localization
- Chromosome: 6
- Chromosomal localization: 6C; 6 30.5 cM
Gene exon/intron organization
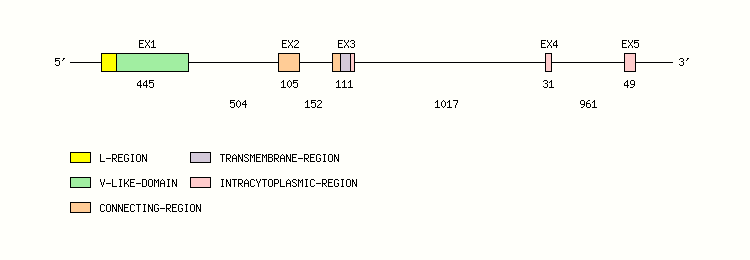
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 8
IMGT reference alleles
| Allele names | Gene functionality | Strain | IMGT reference sequences | ||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||
| CD8A*01 | F | EX1-5 | M22064 [1] | gDNA | |
| CD8A*02 | EX1 | M12819 [2] | gDNA (1) | ||
| EX2-3 | M12975 | ||||
| EX4 | M12976 | ||||
| EX5 | M12977 | ||||
| CD8A*03 | B10.A | EX1-5 | Y00157 [2] | gDNA (2) | |
| CD8A*04 | EX1 | M12978 [3] | gDNA (3) partial | ||
| EX2-3 | M12979 | ||||
| CD8A*05 | NOD | EX1-5 | AK088128 | cDNA (4) | |
| CD8A*06 | NOD | EX1-5 | U34881 [4] | cDNA (5) | |
| CD8A*07 | NOD | EX1-5 | AK088214 | cDNA (6) | |
| CD8A*08 | NOD | EX1-3, 6 | AK088414 | cDNA (7) splicing B | |
IMGT reference sequences (in FASTA format) for the allele(s): CD8A*01 to CD8A*08
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | Strain | IMGT reference sequences | ||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||
| CD8A*02 | F | BALB/c | EX1-5 | M12825 | cDNA |
| EX1-5 | M12052 | ||||
| C57BL/6J | EX1-5 | AK137937 | cDNA partial | ||
| EX1-3, 6 | AK037467 | cDNA splicing B | |||
| EX1-5 | XM_132621 | cDNA | |||
| CD8A*03 | C57BL/6J | EX1-5 | M16981 | cDNA | |
| CD8A*05 | C57BL/6J | EX1-3, 6 | BC030679 | cDNA splicing B | |
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| CD8A*01 | M22064 | 247 aa | 1 | |
| CD8A*02 | M12819 | P01731 | 247 aa | 1 |
| M12975 | 247 aa | 1 | ||
| M12976 | 247 aa | 1 | ||
| M12977 | 247 aa | 1 | ||
| XM_132621 | XP_132621 | 247 aa | 1 | |
| CD8A*03 | Y00157 | 246 aa | 1 | |
| CD8A*04 | M12978 | Q61816 | 220 aa | 1 partial |
| M12979 | 220 aa | 1 partial | ||
| CD8A*05 | AK088128 | Tr:Q542K6 | 247 aa | 1 |
| CD8A*06 | U34881 | Tr:Q60965 | 247 aa | 1 |
| CD8A*07 | AK088214 | Tr:Q8C2Q0 | 247 aa | 1 |
| CD8A*08 | AK088414 | Tr:Q8C2L1 | 222 aa | 2 |
IMGT notes:
- (1) In EX1 c48>t (L-REGION) and g241>a; V81>M, numbering according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN. In EX3 c71>t; P24>L.
- (2) In EX1 c48>t (L-REGION), codon (157gtc159>del#; V53>del#), this deletion may be a sequence error and g241>a; V81>M, numbering according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN. In EX3 c71>t; P24>L.
- (3) In EX1 t60>g; I20>M (L-REGION) and in EX3 c47>t; A16>V and c71>t; P24>L.
- (4) In EX3 c71>t; P24>L (L-REGION).
- (5) In EX1 c46>a; L15>M (L-REGION).
- (6) In EX1 c6>g and t62>c; L21>P (L-REGION) and in EX3 c71>t; P24>L.
- (7) Splicing B (222 aa). Utilize a novel exon EX6 (8 nt). In EX1 t38>c; L13>P (L-REGION), 291a>g, numbering according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN. In EX3 c71>t; P24>L.
IMGT references:
- [1] Youn.H.J, Harriss.J.V. and Gottlieb.P.D., Immunogenetics 28, 345-352 (1988). PMID:3267233
- [2] Nakauchi.H. et al, Nucleic Acids Research, 15, 4337-4347 (1987). PMID:3495785
- [3] Liaw.C.W, Zamoyska.R and Parnes.J.R, The Journal of Immunology 137, 1037-1043 (1986). PMID:3487583
- [4] Johnson-Tardieu.J.M. et al, Immunogenetics 43, 6-12 (1996). PMID:8537123
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
CD8A*01: M22064(g)
Nucleotide sequence
1 atggcctcac cgttgacccg ctttctgtcg ctgaacctgc tgctgctggg tgagtcgatt 61 atcctgggga gtggagaagc taagccacag gcacccgaac tccgaatctt tccaaagaaa 121 atggacgccg aacttggcca gaaggtggac ctggtatgtg aagtgttggg gtccgtttcg 181 caaggatgct cttggctctt ccagaactcc agctccaaac tcccccagcc caccttcgtt 241 gtctatatgg cttcatccca caacaagata acgtgggacg agaagctgaa ttcgtcgaaa 301 ctgttttctg ccgtgaggga cacgaataat aagtacgttc tcaccctgaa caagttcagc 361 aaggaaaacg aaggctacta tttctgctca gtcatcagca actcggtgat gtacttcagt 421 tctgtcgtgc cagtccttca gaaagtgaac tctactacta ccaagccagt gctgcgaact 481 ccctcacctg tgcaccctac cgggacatct cagccccaga gaccagaaga ttgtcggccc 541 cgtggctcag tgaaggggac cggattggac ttcgcctgtg atatttacat ctgggcaccc 601 ttggccggaa tctgcgtggc ccctctgctg tccttgatca tcactctcat ctgctaccac 661 aggagccgaa agcgtgtttg caaatgtccc aggccgctag tcagacagga aggcaagccc 721 agaccttcag agaaaattgt gtaa
Nucleotide sequence in FASTA format (without gaps)
CD8A*01
Amino acid sequence
1 MASPLTRFLS LNLLLLGESI ILGSGEAKPQ APELRIFPKK MDAELGQKVD LVCEVLGSVS 61 QGCSWLFQNS SSKLPQPTFV VYMASSHNKI TWDEKLNSSK LFSAVRDTNN KYVLTLNKFS 121 KENEGYYFCS VISNSVMYFS SVVPVLQKVN STTTKPVLRT PSPVHPTGTS QPQRPEDCRP 181 RGSVKGTGLD FACDIYIWAP LAGICVAPLL SLIITLICYH RSRKRVCKCP RPLVRQEGKP 241 RPSEKIV*
Amino acid sequence in FASTA format (without gap)
CD8A*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN
IMGT databases
- IMGT/3Dstructure-DB: 1bqh
External links
Nomenclature
- HGNC:
Genome databases
Sequence databases
Created: 23/05/2007
Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT