
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Homo sapiens FCER1A
Citing IMGT RPI entry for FCER1A
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens FCER1A
- IMGT gene definition: Fc fragment of IgE, high affinity I, receptor for alpha polypeptide
Chromosomal localization
- Chromosome: 1
- Chromosomal localization: 1q21-q23
Gene exon/intron organization
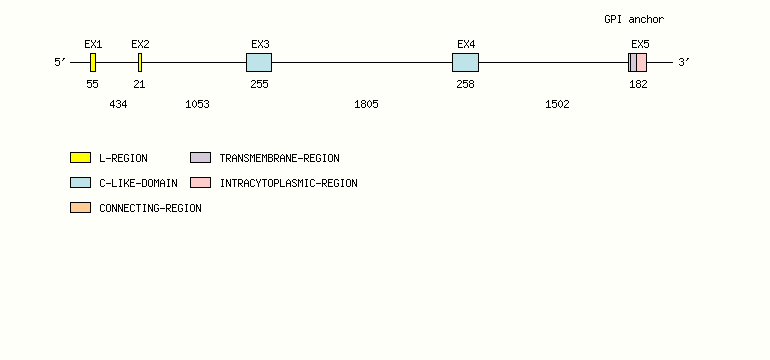
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 2
IMGT reference alleles
| Allele name | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Clone names | Accession numbers | Molecule type | ||
| FCER1A*01 | F | X06948 | cDNA | |
| FCER1A*02 | F | BC015195 | cDNA | |
IMGT reference sequences (in FASTA format) for the allele(s): FCER1A*01 to FCER1A*02
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele name | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Clone names | Accession numbers | Molecule type | ||
| FCER1A*01 | F | J03605 | cDNA | |
| BC005912 | cDNA | |||
Corresponding protein database accession numbers
| Allele name | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| FCER1A*01 | NM_002001 | NP_001992 | 257 aa | |
| X06948 | P12319 | 257 aa | ||
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
FCER1A*01: X06948(c)
Nucleotide sequence
1 atggctcctg ccatggaatc ccctactcta ctgtgtgtag ccttactgtt cttcgctcca 61 gatggcgtgt tagcagtccc tcagaaacct aaggtctcct tgaaccctcc atggaataga 121 atatttaaag gagagaatgt gactcttaca tgtaatggga acaatttctt tgaagtcagt 181 tccaccaaat ggttccacaa tggcagcctt tcagaagaga caaattcaag tttgaatatt 241 gtgaatgcca aatttgaaga cagtggagaa tacaaatgtc agcaccaaca agttaatgag 301 agtgaacctg tgtacctgga agtcttcagt gactggctgc tccttcaggc ctctgctgag 361 gtggtgatgg agggccagcc cctcttcctc aggtgccatg gttggaggaa ctgggatgtg 421 tacaaggtga tctattataa ggatggtgaa gctctcaagt actggtatga gaaccacaac 481 atctccatta caaatgccac agttgaagac agtggaacct actactgtac gggcaaagtg 541 tggcagctgg actatgagtc tgagcccctc aacattactg taataaaagc tccgcgtgag 601 aagtactggc tacaattttt tatcccattg ttggtggtga ttctgtttgc tgtggacaca 661 ggattattta tctcaactca gcagcaggtc acatttctct tgaagattaa gagaaccagg 721 aaaggcttca gacttctgaa cccacatcct aagccaaacc ccaaaaacaa ctga
Nucleotide sequence in FASTA format (without gaps)
FCER1A*01
Amino acid sequence
1 MAPAMESPTL LCVALLFFAP DGVLAVPQKP KVSLNPPWNR IFKGENVTLT CNGNNFFEVS 61 STKWFHNGSL SEETNSSLNI VNAKFEDSGE YKCQHQQVNE SEPVYLEVFS DWLLLQASAE 121 VVMEGQPLFL RCHGWRNWDV YKVIYYKDGE ALKYWYENHN ISITNATVED SGTYYCTGKV 181 WQLDYESEPL NITVIKAPRE KYWLQFFIPL LVVILFAVDT GLFISTQQQV TFLLKIKRTR 241 KGFRLLNPHP KPNPKNN*
Amino acid sequence in FASTA format (without gap)
FCER1A*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays: C-LIKE-DOMAIN
- IMGT Collier de perles: C-LIKE-DOMAIN
IMGT databases
- IMGT/3Dstructure-DB: 1f6a
External links
Genome databases
Sequence databases
Created: 30/07/2004
Last updated: 02/10/2025 15:10
Authors: Thomas Spiesser
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Thomas Spiesser
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT