
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Homo sapiens ICOS
Citing IMGT RPI entry for ICOS
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens ICOS
- IMGT gene definition: inducible T-cell co-stimulator
Chromosomal localization
- Chromosome: 2
- Chromosomal localization: 2q33
Gene exon/intron organization
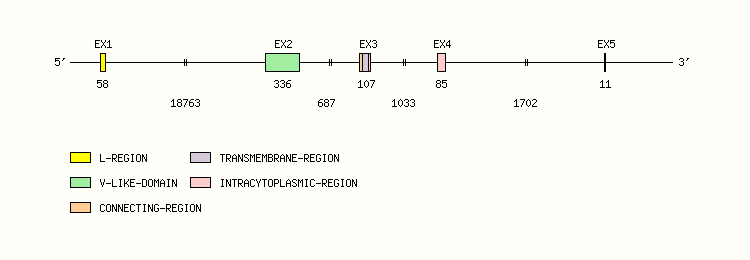
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 1
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| ICOS*01 | F | EX1-5 | AF411058 [1] | gDNA |
IMGT reference sequences (in FASTA format) for the allele(s): ICOS*01
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | |||
|---|---|---|---|---|---|
| Clones | Exons | Accession numbers | Molecule type | ||
| ICOS*01 | F | BAC_22608 | EX1-5 | AF411059 | gDNA |
| RP11-278L16 | EX1-5 | AC103880 | |||
| EX1-5 | AF488346 | ||||
| RP11-278L16 | EX1-5 | AF488347 | |||
| EX1-5 | AJ535718 | ||||
| EX1-5 | AB023135 | cDNA | |||
| MGC:40066 | EX1-5 | AJ277832 | |||
| MGC:39850 | EX1-5 | BC028210 | |||
| EX1-3 | BC028006 | cDNA(1) splicing B | |||
| EX1-5 | NM_012092 | cDNA | |||
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| ICOS*01 | AF411058 | Q9Y6W8 | 199 aa | 1 |
| NM_012092 | NP_036224 | 199 aa | 1 | |
IMGT notes:
- (1) No EX4-5. 168 aa.
IMGT references:
- [1] Ling,V., Wu,P.W. et al. Genomics 78, 155-168 (2001). PMID:11735222
- [2] Strausberg,R.L. Proc. Natl. Acad. Sci. U.S.A. 99, 16899-16903 (2002). PMID:12477932
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
ICOS*01: AF411058(g)
Nucleotide sequence
1 atgaagtcag gcctctggta tttctttctc ttctgcttgc gcattaaagt tttaacagga 61 gaaatcaatg gttctgccaa ttatgagatg tttatatttc acaacggagg tgtacaaatt 121 ttatgcaaat atcctgacat tgtccagcaa tttaaaatgc agttgctgaa aggggggcaa 181 atactctgcg atctcactaa gacaaaagga agtggaaaca cagtgtccat taagagtctg 241 aaattctgcc attctcagtt atccaacaac agtgtctctt tttttctata caacttggac 301 cattctcatg ccaactatta cttctgcaac ctatcaattt ttgatcctcc tccttttaaa 361 gtaactctta caggaggata tttgcatatt tatgaatcac aactttgttg ccagctgaag 421 ttctggttac ccataggatg tgcagccttt gttgtagtct gcattttggg atgcatactt 481 atttgttggc ttacaaaaaa gaagtattca tccagtgtgc acgaccctaa cggtgaatac 541 atgttcatga gagcagtgaa cacagccaaa aaatctagac tcacagatgt gaccctataa
Nucleotide sequence in FASTA format (without gaps)
ICOS*01
Amino acid sequence
1 MKSGLWYFFL FCLRIKVLTG EINGSANYEM FIFHNGGVQI LCKYPDIVQQ FKMQLLKGGQ 61 ILCDLTKTKG SGNTVSIKSL KFCHSQLSNN SVSFFLYNLD HSHANYYFCN LSIFDPPPFK 121 VTLTGGYLHI YESQLCCQLK FWLPIGCAAF VVVCILGCIL ICWLTKKKYS SSVHDPNGEY 181 MFMRAVNTAK KSRLTDVTL*
Amino acid sequence in FASTA format (without gap)
ICOS*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN
External links
Genome databases
- Entrez Gene: 29851
- GENATLAS: ICOS
- GeneCards: GC02P204626
- GDB: 10450295
- OMIM: 604558
Sequence databases
Created: 27/11/2006
Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT