
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Mus musculus ICOS
Citing IMGT RPI entry for ICOS
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Mus musculus ICOS
- IMGT gene definition: inducible T-cell co-stimulator
Chromosomal localization
- Chromosome: 1
- Chromosomal localization: 1C2;1 32.0cM
Gene exon/intron organization
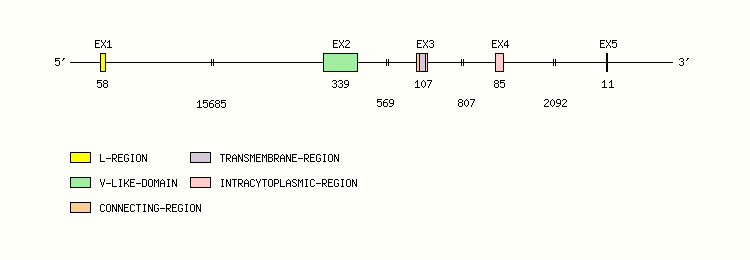
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 2
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| ICOS*01 | F | EX1-5 | AF327184-AF327185[1] | gDNA |
| ICOS*02 | F | EX1-5 | AF257230 | cDNA |
IMGT reference sequences (in FASTA format) for the allele(s): ICOS*01 to ICOS*02
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | |||
|---|---|---|---|---|---|
| Clones | Exons | Accession numbers | Molecule type | ||
| ICOS*01 | F | RP23-148E7 | EX1-5 | AL645744 | gDNA |
| ICOS*01B | F | RP23-148E7 | EX1-4 | AL645744 | gDNA (2) splicing B |
| ICOS*01 | F | MGC:41104 | EX1-5 | BC034852 | cDNA |
| ICOS*02 | F | EX1-5 | AJ250559 | cDNA | |
| EX1-5 | AB023132 | ||||
| EX1-5 | NM_017480 | ||||
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| ICOS*01 | AF327184-AF327185 | Sw:Q9WVS0 | 200 aa | 1 |
| AL645744 | Tr:Q5SUZ8(2) | 223 aa | 2 | |
| ICOS*02 | AF257230 | 220 aa | 1 | |
| NM_017480 | NP_059508 | 220 aa | 1 | |
IMGT notes:
- (1) In the EX1(g20>a,R7>H).
- (2) In the flat file:AL645744, an alternative splicing is proposed with longer EX4(168nt, 55aa) and without EX5, but so far (20/09/05) no cDNA has been described. If confermed by experimental data, this can be refered as splicing B.
IMGT references:
- [1] Tezuka,K. et al, Biochem. Biophys. Res. Commun., 276, 335-345 (2000). PMID:11006126
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
ICOS*01: AF327184(g)
Nucleotide sequence
1 atgaagccgt acttctgccg tgtctttgtc ttctgcttcc taatcagact tttaacagga 61 gaaatcaatg gctcggccga tcataggatg ttttcatttc acaatggagg tgtacagatt 121 tcttgtaaat accctgagac tgtccagcag ttaaaaatgc gattgttcag agagagagaa 181 gtcctctgcg aactcaccaa gaccaaggga agcggaaatg cggtgtccat caagaatcca 241 atgctctgtc tatatcatct gtcaaacaac agcgtctctt ttttcctaaa caacccagac 301 agctcccagg gaagctatta cttctgcagc ctgtccattt ttgacccacc tccttttcaa 361 gaaaggaacc ttagtggagg atatttgcat atttatgaat cccagctctg ctgccagctg 421 aagctctggc tacccgtagg gtgtgcagct ttcgttgtgg tactcctttt tggatgcata 481 cttatcatct ggttttcaaa aaagaaatac ggatccagtg tgcatgaccc taatagtgaa 541 tacatgttca tggcggcagt caacacaaac aaaaagtcta gacttgcagg tgtgacctca 601 taa
Nucleotide sequence in FASTA format (without gaps)
ICOS*01
Amino acid sequence
1 MKPYFCRVFV FCFLIRLLTG EINGSADHRM FSFHNGGVQI SCKYPETVQQ LKMRLFRERE 61 VLCELTKTKG SGNAVSIKNP MLCLYHLSNN SVSFFLNNPD SSQGSYYFCS LSIFDPPPFQ 121 ERNLSGGYLH IYESQLCCQL KLWLPVGCAA FVVVLLFGCI LIIWFSKKKY GSSVHDPNSE 181 YMFMAAVNTN KKSRLAGVTS *
Amino acid sequence in FASTA format (without gap)
ICOS*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN
External links
Genome databases
- Entrez Gene: 54167
- GENATLAS:
- GeneCards:
- GDB:
- OMIM:
Sequence databases
Created: 27/11/2006
Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT