
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Homo sapiens Ly9
Citing IMGT RPI entry for Ly9
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens Ly9
- IMGT gene definition: Lymphocyte antigen 9
Chromosomal localization
- Chromosome: 1
- Chromosomal localization: 1q21.3-q22
Gene exon/intron organization
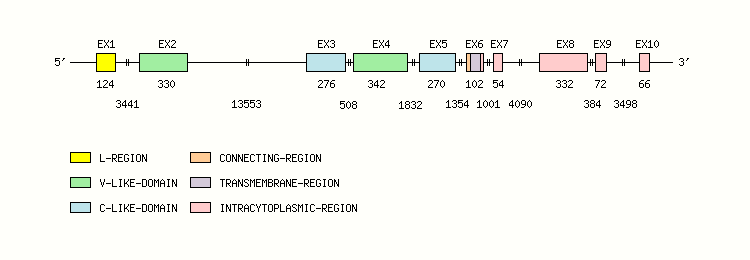
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 4
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| Ly9*01 | F | EX1-10 | AL121985 | gDNA |
| Ly9*02 | F | EX1-10 | AF244129[1] | cDNA (1) |
| Ly9*03 | F | EX1-10 | L42621[2] | cDNA (2) partial |
| Ly9*04 | F | EX3-4,6-10 | BC121049 | cDNA (3) splicing B |
IMGT reference sequences (in FASTA format) for the allele(s): Ly9*01 to Ly9*04
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| Ly9*01 | F | EX1-2, EX11 | BC064485 | cDNA (4) splicing C |
| NM_001033667 | cDNA splicing C | |||
| Ly9*02 | F | EX1-10 | AY007142 | cDNA |
| NM_002348 | cDNA | |||
| EX3-4,6-10 | BC027920 | cDNA splicing B | ||
Corresponding protein database accession numbers
| Allele Name | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| Ly9*01 | AL121985 | Q9HBG7 | 655 aa | 1 |
| NM_001033667 | NP_001028839 | 193 aa | 3 | |
| Ly9*02 | AF244129 | Tr: Q0VAI0 | 654 aa | 1 |
| NM_002348 | NP_002339 | 654 aa | 1 | |
| Ly9*03 | L42621 | 610 aa | 1 | |
| Ly9*04 | BC121049 | 405 aa | 2 | |
IMGT notes:
- (1) In EX3[D2], codon 46-48(cct)>#del; S16>#del, numbering according to IMGT unique numbering for C-DOMAIN and C-LIKE-DOMAIN. In EX8 a189>g; a307>g, M103>V. In EX9 the 3' splice site is shifted to one codon upstream.
- (2) Partial EX1. In EX8 a189>g; a307>g, M103>V. In EX9 the 3' splice site is shifted to one codon upstream.
- (3) Uses alternative start codon 'atg' in EX3. In EX3 c151>g, R51>G. No EX5. In EX9 the 3' splice site is shifted to one codon upstream.
- (4) Splicing C (193 aa). No EX3-10. EX2 do not have the splice site and extends 41 codons beyond the normal splice site.
IMGT references:
- [1] Tovar V. et al., Immunogenetics 51, 788-793 (2000). PMID:10970093
- [2] Sandrin M.S. et al., Immunogenetics 43, 13-19 (1996). PMID:8537117
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
Ly9*01: AL121985(g)
Nucleotide sequence
1 atggtggcac caaagagtca cacagatgac tgggctcctg ggcctttctc cagtaagcca 61 cagaggagtc agctgcaaat attctcttct gttctacaga cctctctcct cttcctgctc 121 atgggactaa gagcctctgg aaaggactca gccccaacag tggtgtcagg gatcctaggg 181 ggttccgtga ctctccccct aaacatctca gtagacacag agattgagaa cgtcatctgg 241 attggtccca aaaatgctct tgctttcgca cgtcccaaag aaaatgtaac cattatggtc 301 aaaagctacc tgggccgact agacatcacc aagtggagtt actccctgtg catcagcaat 361 ctgactctga atgatgcagg atcctacaaa gcccagataa accaaaggaa ttttgaagtc 421 accactgagg aggaattcac cctgttcgtc tatgagcagc tgcaggagcc ccaagtcacc 481 atgaagtctg tgaaggtgtc tgagaacttc tcctgtaaca tcactctaat gtgctccgtg 541 aagggggcag agaaaagtgt tctgtacagc tggaccccaa gggaacccca tgcttctgag 601 tccaatggag gctccattct taccgtctcc cgaacaccat gtgacccaga cctgccatac 661 atctgcacag cccagaaccc cgtcagccag agaagctccc tccctgtcca tgttgggcag 721 ttctgtacag atccaggagc ctccagagga ggaacaacgg gggagactgt ggtaggggtc 781 ctgggagagc cagtcaccct gccacttgca ctcccagcct gccgggacac agagaaggtt 841 gtctggttgt ttaacacatc catcattagc aaagagaggg aagaagcagc aacggcagat 901 ccactcatta aatccaggga tccttacaag aacagggtgt gggtctccag ccaggactgc 961 tccctgaaga tcagccagct gaagatagag gacgccggcc cctaccatgc ctacgtgtgc 1021 tcagaggcct ccagcgtcac cagcatgaca catgtcaccc tgctcatcta ccgcaggctg 1081 aggaagccca aaatcacgtg gagcctcagg cacagtgagg atggcatctg caggatcagc 1141 ctgacctgct ccgtggagga cgggggaaac actgtcatgt acacatggac cccgctgcag 1201 aaggaagctg ttgtgtccca aggggaatca cacctcaatg tctcatggag aagcagtgaa 1261 aatcacccca acctcacatg cacagccagc aaccctgtca gcaggagttc ccaccagttt 1321 ctttctgaga acatctgttc aggacctgag agaaacacaa agctttggat tgggttgttc 1381 ctgatggttt gccttctgtg cgttgggatc ttcagctggt gcatttggaa gcgaaaagga 1441 cggtgttcag tcccagcctt ctgttccagc caagctgagg ccccagcgga tacaccagaa 1501 cccacagctg gccacacgct atactctgtg ctctcccaag gatatgagaa gctggacact 1561 cccctcaggc ctgccaggca acagcctaca cccacctcag acagcagctc tgacagcaac 1621 ctcacaactg aggaggatga ggacaggcct gaggtgcaca agcccatcag tggaagatat 1681 gaggtatttg accaggtcac tcaggagggc gctggacatg acccagcccc tgagggccaa 1741 gcagactatg atcccgtcac tccatatgtc acggaagttg agtctgtggt tggagagaac 1801 accatgtatg cacaagtgtt caacttacag ggaaagaccc cagtttctca gaaggaagag 1861 agctcagcca caatctactg ctccatacgg aaacctcagg tggtggtgcc accaccacaa 1921 cagaatgatc ttgagattcc tgaaagtcct acctatgaaa atttcacctg a
Nucleotide sequence in FASTA format (without gaps)
Ly9*01
Amino acid sequence
1 MVAPKSHTDD WAPGPFSSKP QRSQLQIFSS VLQTSLLFLL MGLRASGKDS APTVVSGILG 61 GSVTLPLNIS VDTEIENVIW IGPKNALAFA RPKENVTIMV KSYLGRLDIT KWSYSLCISN 121 LTLNDAGSYK AQINQRNFEV TTEEEFTLFV YEQLQEPQVT MKSVKVSENF SCNITLMCSV 181 KGAEKSVLYS WTPREPHASE SNGGSILTVS RTPCDPDLPY ICTAQNPVSQ RSSLPVHVGQ 241 FCTDPGASRG GTTGETVVGV LGEPVTLPLA LPACRDTEKV VWLFNTSIIS KEREEAATAD 301 PLIKSRDPYK NRVWVSSQDC SLKISQLKIE DAGPYHAYVC SEASSVTSMT HVTLLIYRRL 361 RKPKITWSLR HSEDGICRIS LTCSVEDGGN TVMYTWTPLQ KEAVVSQGES HLNVSWRSSE 421 NHPNLTCTAS NPVSRSSHQF LSENICSGPE RNTKLWIGLF LMVCLLCVGI FSWCIWKRKG 481 RCSVPAFCSS QAEAPADTPE PTAGHTLYSV LSQGYEKLDT PLRPARQQPT PTSDSSSDSN 541 LTTEEDEDRP EVHKPISGRY EVFDQVTQEG AGHDPAPEGQ ADYDPVTPYV TEVESVVGEN 601 TMYAQVFNLQ GKTPVSQKEE SSATIYCSIR KPQVVVPPPQ QNDLEIPESP TYENFT*
Amino acid sequence in FASTA format (without gap)
Ly9*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN
- HGNC: 6730
- Entrez Gene: 4063
- GENATLAS: 1562
- GeneCards: GC01P159032
- GDB: 1230479
- OMIM: 600684
External links
Nomenclature
Genome databases
Sequence databases
Created: 23/05/2007
Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT