
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Mus musculus Ly9
Citing IMGT RPI entry for Ly9
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Mus musculus Ly9
- IMGT gene definition: Lymphocyte antigen 9
Chromosomal localization
- Chromosome: 1
- Chromosomal localization: 1H3, 1 93.3cM
Gene exon/intron organization
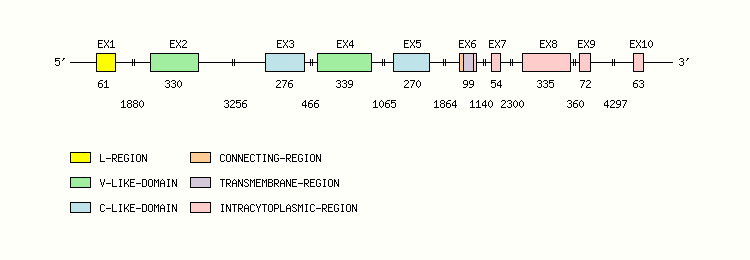
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 9
IMGT reference alleles
| Allele names | Gene functionality | Strains | IMGT reference sequences | ||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||
| Ly9*01 | F | C57BL/6 | EX1-10 | AF244131 | gDNA |
| Ly9*02 | F | C57BL/6 | EX1-10 | AK042288 | cDNA partial |
| Ly9*03 | F | C57BL/6 | EX1-10 | M84412 | cDNA (2) splicing B |
| Ly9*04 | F | BABL/c | EX1-10 | AF244130 | cDNA |
| Ly9*05 | F | 129/Sv | EX1-10 | AF245117, AF245506, AF245118, AF245507, AF245508, AF245509, AF245510, AF246699, AF246700, AF246701 | gDNA |
| Ly9*06 | F | NOD | EX1, EX3-10 | AK088815 | cDNA Splicing C |
| Ly9*07 | F | C57BL/6NcrL | BC055380 | cDNA partial | |
| Ly9*08 | F | C57BL/6NcrL | BC066212 | cDNA partial | |
| Ly9*09 | F | MEL/MpJ | AB196804 | cDNA | |
IMGT reference sequences (in FASTA format) for the allele(s): Ly9*01 to Ly9*09
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | Strains | IMGT reference sequences | ||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||
| Ly9*09 | F | NZB/B1NJ | EX1-10 | AB196805 | cDNA |
| NZW/LacJ | EX1-10 | AB196806 | |||
| BXSB/MpJ | EX1-10 | AB196807 | |||
| NMRI | EX1-10 | BC095921 | |||
Corresponding protein database accession numbers
| Allele Names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| Ly9*01 | AF244131 | Q01965 | 654 aa | 1 |
| Ly9*02 | AK042288 | Tr:Q8C9E4 | 539 aa | 1 partial |
| Ly9*03 | M84412 | 630 aa | 2 | |
| Ly9*04 | AF244130 | 654 aa | 1 | |
| Ly9*05 | AF245117, AF245506, AF245118, AF245507, AF245508, AF245509, AF245510, AF246699, AF246700, AF246701 | 654 aa | 1 | |
| Ly9*06 | AK088815 | Tr:Q8C2D4 | 544 aa | 3 |
| Ly9*07 | BC055380 | Tr:Q7TMP7 | 649 aa | 1 partial |
| Ly9*08 | BC066212 | Tr:Q6NZB6 | 645 aa | 1 partial |
| Ly9*09 | AB196804 | Tr:Q4VBG4 | 654 aa | 1 |
IMGT notes:
- (1) Many alleles with multiple variations, hence description of allelic differences can not be mentioned.
- (2) Splicing B (630 aa). Uses an alternative start codon 21 codons away from normal start codon. In EX10 an insertion at position 41 (41^>ins^g). This cause the frame shift and termination before 3 codons than the normal stop codon.
- (3) Splicing C (544 aa). No EX2.
IMGT references:
- [1] Tovar V. et al., Immunogenetics 51, 788-793 (2000). PMID:10970093
- [2] Sandrin M.S. et al., Immunogenetics 43, 13-19 (1996). PMID:8537117
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
Ly9*01: AF244131(g)
Nucleotide sequence
1 atggcggatc taaagagata ttggtgtgac tgggctctag gtccactctc tgaaaatcca 61 agaatgagtc agcagcagat attttctccc attctttgga ttcctctcct cttcctactc 121 atggggctcg gagcctctgg aaaggaaaca cctccaacag tgatatcagg gatgctaggg 181 ggttctgtga ctttctccct aaacatctca aaggatgcag agattgagca tatcatctgg 241 aattgtcccc caaaggctct tgctttagta ttctacaaaa aagatataac tattctggac 301 aaaggatata atggcagact caaagtcagc gaagatggct actccttgta catgagcaac 361 ctaaccaaaa gtgattcagg atcctaccat gctcagataa accaaaagaa tgttatcctc 421 accacaaata aagagttcac actgcacatc tatgagaagc tccagaagcc tcagatcatc 481 gtggaatctg tgaccccatc cgatactgat tcctgcacct tcaccctaat ctgcactgta 541 aaggggacaa aggacagtgt ccagtacagc tggacccgag aggacaccca tttaaataca 601 tacgatggaa gccacaccct cagggtttcc cagagtgtct gtgaccccga cctaccctat 661 acctgcaaag cctggaatcc agtcagccaa aacagctccc aacctgtccg catctggcaa 721 ttctgcacag gagcctccag aagaaaaaca gcagcgggga agactgtggt aggaatcctg 781 ggagagccag tgaccctgcc cttggaattt cgggccactc gggccacaaa gaatgttgtc 841 tgggtgttta acacgtcggt tatcagccaa gaacggagag gagcagcaac agcggattct 901 cgccgtaagc ccaaaggttc tgaagaacgg agggtgagga cctctgacca ggaccaatcc 961 ctgaagatca gccagctgaa gatggaggac gcgggcccct accatgccta tgtgtgctca 1021 gaggcctccc gagaccccag tgtgagacat ttcaccttgc ttgtctacaa gagactggag 1081 aagtccagtg tcaccaagag tcctgtgcac atgatgaacg gaatctgcga ggttgtcctg 1141 acctgttcag tggacggtgg tggaaacaat gtgacataca catggatgcc tctacaaaac 1201 aaagctgtca tgtcccaagg gaagtcgcac ctcaacgtct cctgggaaag tggtgaacac 1261 ctgcccaact tcacatgcac agcccataac cctgtcagca acagctccag ccagttttct 1321 tctgggacca tctgttcagg ccctgagaga aacaagaggt tttggctcct gctcctcctg 1381 gttttgctct tgttgatgct cattggcggt tacttcattt tgaggaaaaa gaagcagtgt 1441 tcgtctttgg ccaccaggta cagacaagcg gaggtcccag ctgaaatacc agaaacccca 1501 actggccatg gacaattttc tgtgctctcc caacggtatg agaaactaga catgtctgct 1561 aagaccacca ggcatcagcc tacacccacc tcagatacca gctctgagag cagcgcaaca 1621 acagaagagg atgacgaaaa gaccagaatg cacagcactg ctaatagtag aaatcaggtg 1681 tatgacttgg tcacccatca ggacattgca catgccttgg cctatgaggg gcaagtagaa 1741 tatgaagcaa tcactccata tgataaagtg gatgggtcta tggatgaaga ggacatggca 1801 tatatacaag tgtccctgaa tgtgcaggga gagaccccac ttcctcagaa gaaagaagac 1861 tcaaatacaa tctactgctc tgtgcagaag cctaaaaaga cggcacaaac accacagcaa 1921 gatgctgagt ctcctgaaac ccctacctat gaaaatttca cctga
Nucleotide sequence in FASTA format (without gaps)
Ly9*01
Amino acid sequence
1 MADLKRYWCD WALGPLSENP RMSQQQIFSP ILWIPLLFLL MGLGASGKET PPTVISGMLG 61 GSVTFSLNIS KDAEIEHIIW NCPPKALALV FYKKDITILD KGYNGRLKVS EDGYSLYMSN 121 LTKSDSGSYH AQINQKNVIL TTNKEFTLHI YEKLQKPQII VESVTPSDTD SCTFTLICTV 181 KGTKDSVQYS WTREDTHLNT YDGSHTLRVS QSVCDPDLPY TCKAWNPVSQ NSSQPVRIWQ 241 FCTGASRRKT AAGKTVVGIL GEPVTLPLEF RATRATKNVV WVFNTSVISQ ERRGAATADS 301 RRKPKGSEER RVRTSDQDQS LKISQLKMED AGPYHAYVCS EASRDPSVRH FTLLVYKRLE 361 KSSVTKSPVH MMNGICEVVL TCSVDGGGNN VTYTWMPLQN KAVMSQGKSH LNVSWESGEH 421 LPNFTCTAHN PVSNSSSQFS SGTICSGPER NKRFWLLLLL VLLLLMLIGG YFILRKKKQC 481 SSLATRYRQA EVPAEIPETP TGHGQFSVLS QRYEKLDMSA KTTRHQPTPT SDTSSESSAT 541 TEEDDEKTRM HSTANSRNQV YDLVTHQDIA HALAYEGQVE YEAITPYDKV DGSMDEEDMA 601 YIQVSLNVQG ETPLPQKKED SNTIYCSVQK PKKTAQTPQQ DAESPETPTY ENFT*
Amino acid sequence in FASTA format (without gap)
Ly9*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT RepertoireChromosomal localization
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN
- HGNC:
External links
Nomenclature
Genome databases
Sequence databases
Created: 23/05/2007
Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT