
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Homo sapiens MPZ
Citing IMGT RPI entry for MPZ
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens MPZ
- IMGT gene definition: Homo sapiens Myelin protein zero (charcot-Marie-tooth neuropathy 1B)
Chromosomal localization
- Chromosome: 1
- Chromosomal localization: 1q22
Gene exon/intron organization
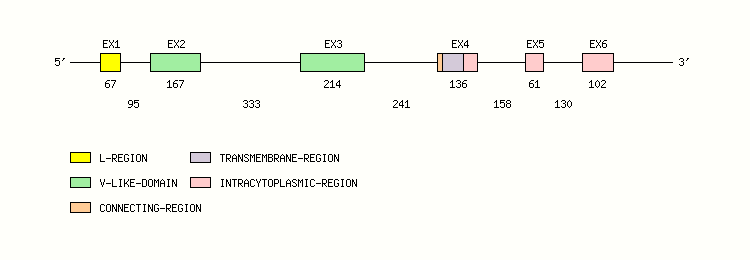
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 4
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| MPZ*01 | F | EX1-6 | D14720 [1] | gDNA |
| MPZ*02 | F | EX1-6 | AL592295 | gDNA (1) |
| MPZ*03 | F | EX1-6 | L24893 [2] | gDNA (2) splicing B |
| MPZ*04 | F | EX1-6 | Z31718 [3] | gDNA (3) splicing B |
IMGT reference sequences (in FASTA format) for the allele(s): MPZ*01 to MPZ*04
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | Partiality | ||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||
| MPZ*01 | F | EX1-3 | S66705 | cDNA (5) splicing B | Partial |
| MPZ*02 | F | EX1-6 | BC006491 | cDNA | |
| BT006165 | cDNA | ||||
| EX1-5 | U10018 | gDNA splicing B (4) | Partial | ||
| EX1-6 | NM_000530 | cDNA | |||
| MPZ*03 | F | EX1-6 | D10537 | cDNA | |
Corresponding protein database accession numbers
| Allele Name | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| MPZ*01 | D14720 | 258 aa | 1 | |
| MPZ*02 | AL592295 | Q5VTH4 | 258 aa | 1 |
| NM_000530 | NP_000521 | 258 aa | 1 | |
| MPZ*03 | L24893 | P25189 | 248 aa | 2 |
| MPZ*04 | Z31718 | Q14902 | 251 aa | 2 |
IMGT notes:
- (1) V-LIKE-DOMAIN [D] is encoded by EX2 and EX3
- (2) In EX3 [D] 92a>g (257a>g) in V-LIKE-DOMAIN, numbering according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN.
- (3) Utilizes an alternate start codon 30 nt downstream. In EX2 [D] 149a>g (138.3a>g) and in EX3 [D] 84c>t (252t>c) and 132t>c (297c>t) in V-LIKE-DOMAIN, numbering according to IMGT unique numbering for V-LIKE-DOMAIN.
- (4) Utilizes an alternate start codon 30 nt downstream. In EX6 insertion of 2 nt at position 15 (15^16>ins^gc) which most probably arise by sequence error ot typing error. This insertion lead to the frame shift.
- (5) Partial. No EX1.
- (6) Splicing B. In EX2[D] at position 108 deletion of 3 nt (109-111ctc>del#); 37I>del#. This most probably result from sequencing error or typing error.
IMGT references:
- [1] Hayasaka K. et al., Biochem. Biophys.res. Commun.180, 515-518 (1991). PMID:1719967
- [2] Pham Dinh D. et al., Hum. Mol. Genet.2, 2051-2054 (1993). PMID:7509228
- [3] Rautenstrauss B. et al., Hum. Mol. Genet.3, 1701-1702 (1994). PMID:7530550
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
MPZ*01: D14720(g)
Nucleotide sequence
1 atgctccggg cccctgcccc tgccccagct atggctcctg gggctccctc atccagcccc 61 agccctatcc tggctgtgct gctcttctct tctttggtgc tgtccccggc ccaggccatc 121 gtggtttaca ccgacaggga ggtccatggt gctgtgggct cccgggtgac cctgcactgc 181 tccttctggt ccagtgagtg ggtctcagat gacatctcct tcacctggcg ctaccagccc 241 gaaggaggca gagatgccat ttcgatcttc cactatgcca agggacaacc ctacattgac 301 gaggtgggga ccttcaaaga gcgcatccag tgggtagggg accctcgctg gaaggatggc 361 tccattgtca tacacaacct agactacagt gacaatggca cgttcacttg tgacgtcaaa 421 aaccctccag acatagtggg caagacctct caggtcacgc tgtatgtctt tgaaaaagtg 481 ccaactaggt acggggtcgt tctgggagct gtgatcgggg gtgtcctcgg ggtggtgctg 541 ttgctgctgc tgcttttcta cgtggttcgg tactgctggc tacgcaggca ggcggccctg 601 cagaggaggc tcagtgctat ggagaagggg aaattgcaca agccaggaaa ggacgcgtcg 661 aagcgcgggc ggcagacgcc agtgctgtat gcaatgctgg accacagcag aagcaccaaa 721 gctgtcagtg agaagaaggc caaggggctg ggggagtctc gcaaggataa gaaatag
Nucleotide sequence in FASTA format (without gaps)
MPZ*01
Amino acid sequence
1 MLRAPAPAPA MAPGAPSSSP SPILAVLLFS SLVLSPAQAI VVYTDREVHG AVGSRVTLHC 61 SFWSSEWVSD DISFTWRYQP EGGRDAISIF HYAKGQPYID EVGTFKERIQ WVGDPRWKDG 121 SIVIHNLDYS DNGTFTCDVK NPPDIVGKTS QVTLYVFEKV PTRYGVVLGA VIGGVLGVVL 181 LLLLLFYVVR YCWLRRQAAL QRRLSAMEKG KLHKPGKDAS KRGRQTPVLY AMLDHSRSTK 241 AVSEKKAKGL GESRKDKK*
Amino acid sequence in FASTA format (without gap)
MPZ*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays: V-LIKE-DOMAINs
- IMGT Collier de perles: V-LIKE-DOMAIN
IMGT databases
- IMGT/3Dstructure-DB: 1neu
External links
Genome databases
- Entrez Gene: 4359
- GENATLAS: MPZ
- GeneCards: GC01M158087
- GDB: MPZ
- OMIM: 159440
Sequence databases
Created: 20/02/2007
Last updated: 02/10/2025 15:10
Authors: Nelly Rozas, Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Nelly Rozas, Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT