
IMGT Repertoire (RPI)
Other IgSF entries
- Mus musculus: PDCD1
IMGT RPI entry from gene to protein for Homo sapiens PDCD1
Citing IMGT RPI entry for PDCD1
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens PDCD1
- IMGT gene definition: programmed cell death 1
Chromosomal localization
- Chromosome: 2
- Chromosomal localization: 2q37.3
Gene exon/intron organization
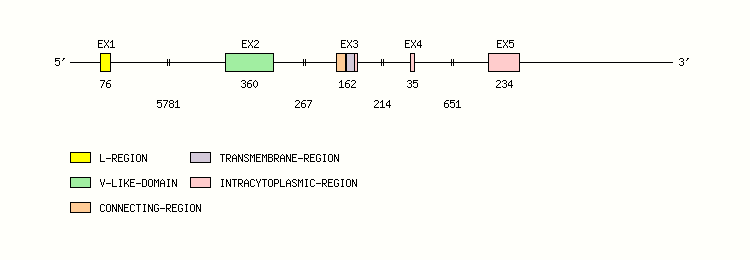
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 5
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| PDCD1*01 | F | EX1-5 | AF363458 [1] | gDNA |
| PDCD1*02 | F | EX1-5 | AY238517 | cDNA (1) |
| PDCD1*03 | F | EX1-5 | BC074740 [2] | cDNA (2) |
| PDCD1*04 | F | EX1-5 | L27440 [3] | cDNA (3) |
| PDCD1*05 | F | EX1-5 | U64863 [3] | cDNA (4) |
IMGT reference sequences (in FASTA format) for the allele(s): PDCD1*01 to PDCD1*05
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | |||
|---|---|---|---|---|---|
| Clones | Exons | Accession numbers | Molecule type | ||
| PDCD1*05 | F | EX1-5 | NM_005018 | gDNA | |
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide Databases | Protein Databases | |||
| PDCD1*01 | AF363458 | 288 aa | 1 | |
| PDCD1*02 | AY238517 | 288 aa | 1 | |
| PDCD1*03 | BC074740 | 288 aa | 1 | |
| PDCD1*04 | L27440 | 288 aa | 1 | |
| PDCD1*05 | U64863 | Q15116 | 288 aa | 1 |
| NM_005018 | NP_005009 | 288 aa | 1 | |
IMGT notes:
- (1) In EX5 c177>t.
- (2) EX2[D] c165>t, numbering according to the unique IMGT numbering for the V-DOMAIN and V-LIKE-DOMIAN.
- (3) In EX3 c48>t; P16>S and in EX5 c177>t.
- (4) c20>t; S7>F in EX2 according to the IMGT unique numbering for the V-LIKE-DOMAIN.
IMGT references:
- [1] Prokunina.L. et al., Natural Genetics, 32, 666-669, (2002). PMID:12402038
- [2] Srausberg.R.L. et al., Proc Natl Acad Sci U S A, 99(26), 16899-903, (2002). PMID:12477932
- [3] Shinohara.T. et al., Genomics, 23 (3), 704-706, (1994). PMID:7851902
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
PDCD1*01: AF363458(g)
Nucleotide sequence
1 atgcagatcc cacaggcgcc ctggccagtc gtctgggcgg tgctacaact gggctggcgg 61 ccaggatggt tcttagactc cccagacagg ccctggaacc cccccacctt ctccccagcc 121 ctgctcgtgg tgaccgaagg ggacaacgcc accttcacct gcagcttctc caacacatcg 181 gagagcttcg tgctaaactg gtaccgcatg agccccagca accagacgga caagctggcc 241 gccttccccg aggaccgcag ccagcccggc caggactgcc gcttccgtgt cacacaactg 301 cccaacgggc gtgacttcca catgagcgtg gtcagggccc ggcgcaatga cagcggcacc 361 tacctctgtg gggccatctc cctggccccc aaggcgcaga tcaaagagag cctgcgggca 421 gagctcaggg tgacagagag aagggcagaa gtgcccacag cccaccccag cccctcaccc 481 aggccagccg gccagttcca aaccctggtg gttggtgtcg tgggcggcct gctgggcagc 541 ctggtgctgc tagtctgggt cctggccgtc atctgctccc gggccgcacg agggacaata 601 ggagccaggc gcaccggcca gcccctgaag gaggacccct cagccgtgcc tgtgttctct 661 gtggactatg gggagctgga tttccagtgg cgagagaaga ccccggagcc ccccgtgccc 721 tgtgtccctg agcagacgga gtatgccacc attgtctttc ctagcggaat gggcacctca 781 tcccccgccc gcaggggctc agccgacggc cctcggagtg cccagccact gaggcctgag 841 gatggacact gctcttggcc cctctaa
Nucleotide sequence in FASTA format (without gaps)
PDCD1*01
Amino acid sequence
1 MQIPQAPWPV VWAVLQLGWR PGWFLDSPDR PWNPPTFSPA LLVVTEGDNA TFTCSFSNTS 61 ESFVLNWYRM SPSNQTDKLA AFPEDRSQPG QDCRFRVTQL PNGRDFHMSV VRARRNDSGT 121 YLCGAISLAP KAQIKESLRA ELRVTERRAE VPTAHPSPSP RPAGQFQTLV VGVVGGLLGS 181 LVLLVWVLAV ICSRAARGTI GARRTGQPLK EDPSAVPVFS VDYGELDFQW REKTPEPPVP 241 CVPEQTEYAT IVFPSGMGTS SPARRGSADG PRSAQPLRPE DGHCSWPL*
Amino acid sequence in FASTA format (without gap)
PDCD1*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- IMGT Alignment of alleles:
- IMGT Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN
External links
Genome databases
- Entrez Gene: 29851
- GENATLAS: ICOS
- GeneCards: GC02P204626
- GDB: 10450295
- OMIM: 604558
Sequence databases
Created: 27/11/2006
Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT