
IMGT Repertoire (RPI)
- Homo sapiens: RAET1E
IMGT RPI entry from gene to protein for Homo sapiens RAET1H
IMGT gene name and definition
- IMGT gene name: Homo sapiens RAET1H
- IMGT gene definition: retinoic acid early transcript 1 H, UL 16 binding protein 2 (ULBP2)
Chromosomal localization
- Chromosome: 6
- Chromosomal localization: 6q25.1
Locus representation
Homo sapiens RAET1H locus 6q25.1
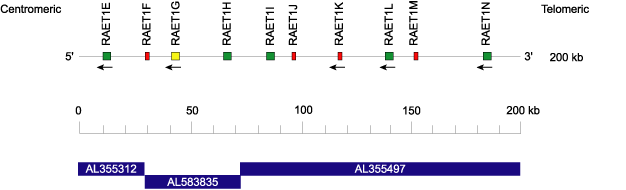
The human RAET1 locus [1] located at 6q25.1 spans 200 kilobases from 150,230 to 150,430 kb (Ensembl, 09/06/2004).
Clones (in blue) are in forward (FWD) orientation on the chromosome. They overlap by about 100 base pairs of complete similarity. An additional 100 base pairs are dissimilar probably for cloning reasons.
Gene exon/intron organization
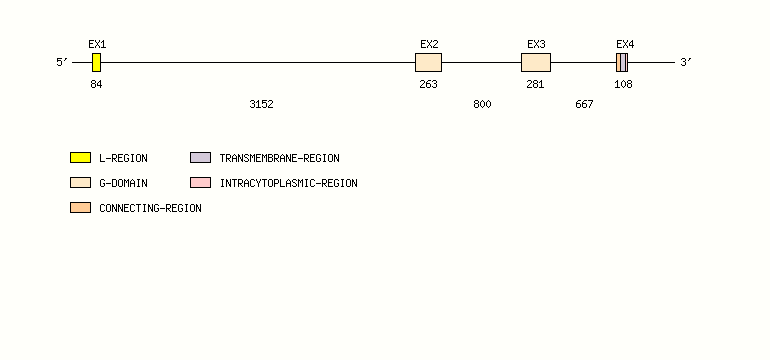
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 2
IMGT reference alleles
| Allele name | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Clone names | Accession numbers | Molecule type | ||
| RAET1H*01 | F | RP11-244K5 | AL583835 [1] | gDNA |
| RAET1H*02 | F | AB052906 | cDNA | |
IMGT reference sequences (in FASTA format) for the allele(s): RAET1H*01 to RAET1H*02
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele name | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Clone names | Accession numbers | Molecule type | ||
| RAET1H*01 | F | AF304378 | cDNA | |
| AY358665 | cDNA | |||
| AY026825 | cDNA (1) | |||
| RAET1H*02 | F | BC034689 | cDNA | |
Corresponding protein database accession numbers
| Allele name | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| RAET1H*01 | NM_025217 | NP_079493 | 246 aa | |
| AF304378 | Sw: Q9BZM5 | 246 aa | ||
| AY358665 | ||||
| AY026825 | ||||
| RAET1H*02 | AB052906 | |||
| BC034689 | ||||
- (1) Owing to an undertermined nucleotide (m for a or c) at position 369, this sequence could be indifferently assigned to allele *01 or *02.
- [1] Radosavljevic, M. et al., Genomics, 79, 114-123 (2002). PMID:11827464
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
RAET1H*01: AL583835(g) AF304378(c)
Nucleotide sequence
1 atggcagcag ccgccgctac caagatcctt ctgtgcctcc cgcttctgct cctgctgtcc 61 ggctggtccc gggctgggcg agccgaccct cactctcttt gctatgacat caccgtcatc 121 cctaagttca gacctggacc acggtggtgt gcggttcaag gccaggtgga tgaaaagact 181 tttcttcact atgactgtgg caacaagaca gtcacacctg tcagtcccct ggggaagaaa 241 ctaaatgtca caacggcctg gaaagcacag aacccagtac tgagagaggt ggtggacata 301 cttacagagc aactgcgtga cattcagctg gagaattaca cacccaagga acccctcacc 361 ctgcaggcaa ggatgtcttg tgagcagaaa gctgaaggac acagcagtgg atcttggcag 421 ttcagtttcg atgggcagat cttcctcctc tttgactcag agaagagaat gtggacaacg 481 gttcatcctg gagccagaaa gatgaaagaa aagtgggaga atgacaaggt tgtggccatg 541 tccttccatt acttctcaat gggagactgt ataggatggc ttgaggactt cttgatgggc 601 atggacagca ccctggagcc aagtgcagga gcaccactcg ccatgtcctc aggcacaacc 661 caactcaggg ccacagccac caccctcatc ctttgctgcc tcctcatcat cctcccctgc 721 ttcatcctcc ctggcatctg a
Amino acid sequence
1 MAAAAATKIL LCLPLLLLLS GWSRAGRADP HSLCYDITVI PKFRPGPRWC AVQGQVDEKT 61 FLHYDCGNKT VTPVSPLGKK LNVTTAWKAQ NPVLREVVDI LTEQLRDIQL ENYTPKEPLT 121 LQARMSCEQK AEGHSSGSWQ FSFDGQIFLL FDSEKRMWTT VHPGARKMKE KWENDKVVAM 181 SFHYFSMGDC IGWLEDFLMG MDSTLEPSAG APLAMSSGTT QLRATATTLI LCCLLIILPC 241 FILPGI*
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: G-LIKE-DOMAINs
External links
Nomenclature
- HGNC: 14894
Genome databases
Sequence databases
Last updated: 02/10/2025 15:10
Authors: Nathalie Clavert
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news




© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT