
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Homo sapiens SLAMF6
Citing IMGT RPI entry for SLAMF6
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens SLAMF6
- IMGT gene definition: SLAM Family Member 6
Chromosomal localization
- Chromosome: 1
- Chromosomal localization: 1q23.2
Gene exon/intron organization
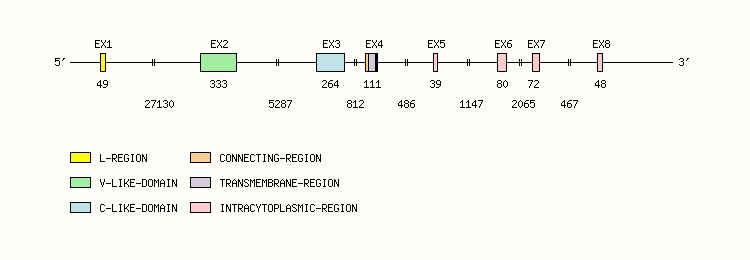
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 1
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| SLAMF6*01 | F | EX1-8 | AJ306388 | cDNA |
IMGT reference sequences (in FASTA format) for the allele(s): SLAMF6*01
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| SLAMF6*01 | F | EX1-8 | AL832854 | cDNA |
| AJ306388 | cDNA | |||
| AY358159 | cDNA | |||
| AL138930 | gDNA splcing B (1) | |||
| AJ277141 | cDNA | |||
| AK125624 | cDNA | |||
| NM_052931 | cDNA | |||
| BC113893 | cDNA | |||
| EX1-5 | BC090928 | cDNA splicing C (2) | ||
Corresponding protein database accession numbers
| SLAMF6 | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| SLAMF6*01 | AJ306388 | 332 aa | 1 | |
| NM_052931 | NP_443163 | 331 aa | 2 | |
| BC090928 | Tr:Q5BKU7 | 271 aa | 3 | |
IMGT notes:
- (1) Splicing B (332 aa). In EX6, it utilizes an alternative 5' splice site 1 codon after the normal splice site.
- (2) Splicing C (271 aa). In EX5 there is no splice site and ends 6 codons beyond the normal 3' splice site.
IMGT references:
- [1] Bottino C. et al., J. Exp. Med. 194 (3), 235-246 (2001). PMID:11489943
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
SLAMF6*01: AL138930(g) AJ277141(c)
Nucleotide sequence
1 atgttgtggc tgttccaatc gctcctgttt gtcttctgct ttggcccagg gaatgtagtt 61 tcacaaagca gcttaacccc attgatggtg aacgggattc tgggggagtc agtaactctt 121 cccctggagt ttcctgcagg agagaaggtc aacttcatca cttggctttt caatgaaaca 181 tctcttgcct tcatagtacc ccatgaaacc aaaagtccag aaatccacgt gactaatccg 241 aaacagggaa agcgactgaa cttcacccag tcctactccc tgcaactcag caacctgaag 301 atggaagaca caggctctta cagagcccag atatccacaa agacctctgc aaagctgtcc 361 agttacactc tgaggatatt aagacaactg aggaacatac aagttaccaa tcacagtcag 421 ctatttcaga atatgacctg tgagctccat ctgacttgct ctgtggagga tgcagatgac 481 aatgtctcat tcagatggga ggccttggga aacacacttt caagtcagcc aaacctcact 541 gtctcctggg accccaggat ttccagtgaa caggactaca cctgcatagc agagaatgct 601 gtcagtaatt tatccttctc tgtctctgcc cagaagcttt gcgaagatgt taaaattcaa 661 tatacagata ccaaaatgat tctgtttatg gtttctggga tatgcatagt cttcggtttc 721 atcatactgc tgttacttgt tttgaggaaa agaagagatt ccctatcttt gtctactcag 781 cgaacacagg gccccgcaga gtccgcaagg aacctagagt atgtttcagt gtctccaacg 841 aacaacactg tgtatgcttc agtcactcat tcaaacaggg aaacagaaat ctggacacct 901 agagaaaatg atactatcac aatttactcc acaattaatc attccaaaga gagtaaaccc 961 actttttcca gggcaactgc ccttgacaat gtcgtgtaa
Nucleotide sequence in FASTA format (without gaps)
SLAMF6*01
Amino acid sequence
1 MLWLFQSLLF VFCFGPGNVV SQSSLTPLMV NGILGESVTL PLEFPAGEKV NFITWLFNET 61 SLAFIVPHET KSPEIHVTNP KQGKRLNFTQ SYSLQLSNLK MEDTGSYRAQ ISTKTSAKLS 121 SYTLRILRQL RNIQVTNHSQ LFQNMTCELH LTCSVEDADD NVSFRWEALG NTLSSQPNLT 181 VSWDPRISSE QDYTCIAENA VSNLSFSVSA QKLCEDVKIQ YTDTKMILFM VSGICIVFGF 241 IILLLLVLRK RRDSLSLSTQ RTQGPAESAR NLEYVSVSPT NNTVYASVTH SNRETEIWTP 301 RENDTITIYS TINHSKESKP TFSRATALDN VV*
Amino acid sequence in FASTA format (without gap)
SLAMF6*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN
- IMGT/3Dstructure-DB: 2if7
IMGT databases
External links
Nomenclature
- HGNC: 21392
Genome databases
- Entrez Gene: 114836
- GENATLAS: 28710
- GeneCards: GC01M157267
- GDB: 11523265
- OMIM: 606446
Sequence databases
Created: 23/05/2007
Last updated: 02/10/2025 15:10
Authors: Stéphanie Douvres, Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Stéphanie Douvres, Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT