
IMGT Repertoire (RPI)
Other IgSF entries
- Mus musculus: BTLA
IMGT RPI entry from gene to protein for Homo sapiens BTLA
Citing IMGT RPI entry for BTLA
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens BTLA
- IMGT gene definition: B and T lymphocyte associated
Chromosomal localization
- Chromosome: 3
- Chromosomal localization: 3q13.2
Gene exon/intron organization
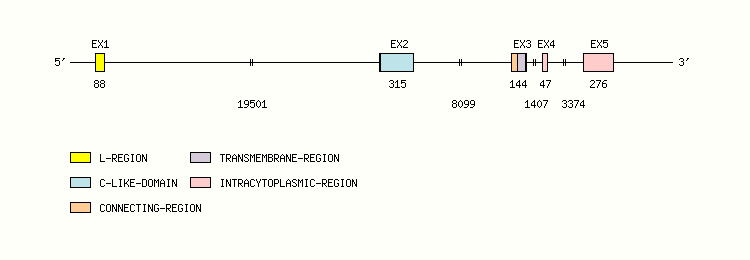
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 4
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| BTLA*01 | F | EX1-5 | AJ717664 | cDNA |
| BTLA*02 | F | EX1-5 | NM_181780 | gDNA(1) |
| BTLA*03 | F | EX1-5 | AK131204 | cDNA(2) |
| BTLA*04 | F | EX1-5 | AY293286 | cDNA(3) |
IMGT reference sequences (in FASTA format) for the allele(s): BTLA*01 to BTLA*04
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| BTLA*01 | F | EX1-5 | BC107092 | cDNA |
| BC120602 | cDNA | |||
| EX1-2, EX4-5 | DQ198368(4) | cDNA splicingB | ||
Corresponding protein database accession numbers
| BTLA | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide Databases | Protein Databases | |||
| BTLA*01 | AJ717664 | Q02242 | 289 aa | 1 |
| BTLA*02 | NM_181780 | NP_032824 | 289 aa | 1 |
| BTLA*03 | AK131204 | 283 aa | ||
| BTLA*04 | AY293286 | 289 aa | ||
IMGT notes:
- (1) In EX2, t273>c numbering according to IMGT unique numbering for C-DOMAIN and C-LIKE-DOMAIN.
- (2) In EX2, t273>c numbering according to IMGT unique numbering for C-DOMAIN and C-LIKE-DOMAIN and in EX5 t62>c; L21>P.
- (3) mutations are many.
- (4) No EX3.
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
BTLA*01: AJ717664(c)
Nucleotide sequence
1 atgaagacat tgcctgccat gcttggaact gggaaattat tttgggtctt cttcttaatc 61 ccatatctgg acatctggaa catccatggg aaagaatcat gtgatgtaca gctttatata 121 aagagacaat ctgaacactc catcttagca ggagatccct ttgaactaga atgccctgtg 181 aaatactgtg ctaacaggcc tcatgtgact tggtgcaagc tcaatggaac aacatgtgta 241 aaacttgaag atagacaaac aagttggaag gaagagaaga acatttcatt tttcattcta 301 cattttgaac cagtgcttcc taatgacaat gggtcatacc gctgttctgc aaattttcag 361 tctaatctca ttgaaagcca ctcaacaact ctttatgtga cagatgtaaa aagtgcctca 421 gaacgaccct ccaaggacga aatggcaagc agaccctggc tcctgtatag tttacttcct 481 ttggggggat tgcctctact catcactacc tgtttctgcc tgttctgctg cctgagaagg 541 caccaaggaa agcaaaatga actctctgac acagcaggaa gggaaattaa cctggttgat 601 gctcacctta agagtgagca aacagaagca agcaccaggc aaaattccca agtactgcta 661 tcagaaactg gaatttatga taatgaccct gacctttgtt tcaggatgca ggaagggtct 721 gaagtttatt ctaatccatg cctggaagaa aacaaaccag gcattgttta tgcttccctg 781 aaccattctg tcattggact gaactcaaga ctggcaagaa atgtaaaaga agcaccaaca 841 gaatatgcat ccatatgtgt gaggagttaa
Nucleotide sequence in FASTA format (without gaps)
BTLA*01
Amino acid sequence
1 MKTLPAMLGT GKLFWVFFLI PYLDIWNIHG KESCDVQLYI KRQSEHSILA GDPFELECPV 61 KYCANRPHVT WCKLNGTTCV KLEDRQTSWK EEKNISFFIL HFEPVLPNDN GSYRCSANFQ 121 SNLIESHSTT LYVTDVKSAS ERPSKDEMAS RPWLLYSLLP LGGLPLLITT CFCLFCCLRR 181 HQGKQNELSD TAGREINLVD AHLKSEQTEA STRQNSQVLL SETGIYDNDP DLCFRMQEGS 241 EVYSNPCLEE NKPGIVYASL NHSVIGLNSR LARNVKEAPT EYASICVRS*
Amino acid sequence in FASTA format (without gap)
BTLA*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays: C-LIKE-DOMAINs
- IMGT Collier de perles: C-LIKE-DOMAIN
IMGT databases
- IMGT/3Dstructure-DB: 2aw2
External links
Nomenclature
- HGNC: 21087
Genome databases
- Entrez Gene: 151888
- GENATLAS: BTLA
- GeneCards: GC03M113667
- GDB: 11513504
- OMIM: 607925
Sequence databases
Created: 23/11/2006
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2025 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT