
IMGT Repertoire (RPI)
Other CD2 Family entries
IMGT RPI entry from gene to protein for Homo sapiens CD244
Citing IMGT RPI entry for CD244
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens CD244
- IMGT gene definition: Natural killer cell receptor 2B4
Chromosomal localization
- Chromosome: 1
- Chromosomal localization: 1q23.3
Gene exon/intron organization
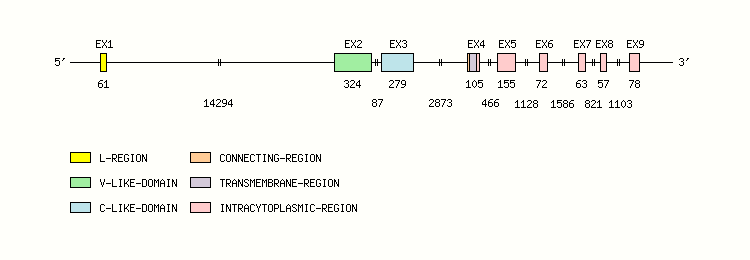
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 2
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| CD244*01 | F | EX1-9 | AF242540[1] | cDNA |
| CD244*02 | F | EX1-9 | AF105261[2] | cDNA (1)splicing B |
IMGT reference sequences (in FASTA format) for the allele(s): CD244*01 to CD244*02
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| CD244*02 | F | EX1-9 | AL354714 | cDNA |
| AF107761 | cDNA | |||
| AF117711 | cDNA | |||
| AJ245375 | cDNA | |||
| AF145782 | cDNA | |||
| BC053985 | cDNA | |||
| BC028073 | cDNA | |||
| NM_016382 | cDNA | |||
| EX1-7,10 | AJ245377 | cDNA (2) splicing C | ||
| EX1-2,4-9 | AJ245376 | cDNA (3) splicing D | ||
Corresponding protein database accession numbers
| CD244 | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| CD244*01 | AF105261 | Q9BZW8 | 365 aa | 1 |
| AL354714 | Q5VYI2 | 365 aa | 2 | |
| AJ245377 | Q5VYI5 | 329 aa | 3 | |
| AJ245376 | Q5VYI6 | 273 aa | 4 | |
| AF363452 | 106 aa | 5 | ||
| NM_016382 | NP_057466 | 365 aa | 1 | |
| CD244*02 | AF242540 | Q9BZW8 | 370 aa | 1 |
IMGT notes:
- (1) Splicing B (365 aa). Internal alternative splicing within EX3. 15 nt away from 5' splice site. In EX3 [D2] 360t>c, numbering according to IMGT unique numbering for C-DOMAIN and C-LIKE-DOMAIN.
- (2) Splicing C (329 aa). No EX8 and EX9. Utilize a novel exon (EX10) of 9 codons.
- (3) Splicing D (273 aa). No EX3.
IMGT references:
- [1] Nakajima H. et al., Eur. J. Immunol. 29, 1676-1683 (1999). PMID:10359122
- [2] Kumaresan P.R. and Mathew P.A., Immunogenetics 51, 987-992 (2000). PMID:11003394
- [3] Parolini and al., J. Exp. Med. 192, 337-346 (2000). PMID:10934222
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
CD244*01: AF242540(c)
Nucleotide sequence
1 atgctggggc aagtggtcac cctcatactc ctcctgctcc tcaaggtgta tcagggcaaa 61 ggatgccagg gatcagctga ccatgtggtt agcatctcgg gagtgcctct tcagttacaa 121 ccaaacagca tacagacgaa ggttgacagc attgcatgga agaagttgct gccctcacaa 181 aatggatttc atcacatatt gaagtgggag aatggctctt tgccttccaa tacttccaat 241 gatagattca gttttatagt caagaacttg agtcttctca tcaaggcagc tcagcagcag 301 gacagtggcc tctactgcct ggaggtcacc agtatatctg gaaaagttca gacagccacg 361 ttccaggttt ttgtatttga taaagttgag aaaccccgcc tacaggggca ggggaagatc 421 ctggacagag ggagatgcca agtggctctg tcttgcttgg tctccaggga tggcaatgtg 481 tcctatgctt ggtacagagg gagcaagctg atccagacag cagggaacct cacctacctg 541 gacgaggagg ttgacattaa tggcactcac acatatacct gcaatgtcag caatcctgtt 601 agctgggaaa gccacaccct gaatctcact caggactgtc agaatgccca tcaggaattc 661 agattttggc cgtttttggt gatcatcgtg attctaagcg cactgttcct tggcaccctt 721 gcctgcttct gtgtgtggag gagaaagagg aaggagaagc agtcagagac cagtcccaag 781 gaatttttga caatttacga agatgtcaag gatctgaaaa ccaggagaaa tcacgagcag 841 gagcagactt ttcctggagg ggggagcacc atctactcta tgatccagtc ccagtcttct 901 gctcccacgt cacaagaacc tgcatataca ttatattcat taattcagcc ttccaggaag 961 tctggatcca ggaagaggaa ccacagccct tccttcaata gcactatcta tgaagtgatt 1021 ggaaagagtc aacctaaagc ccagaaccct gctcgattga gccgcaaaga gctggagaac 1081 tttgatgttt attcctag
Nucleotide sequence in FASTA format (without gaps)
CD244*01
Amino acid sequence
1 MLGQVVTLIL LLLLKVYQGK GCQGSADHVV SISGVPLQLQ PNSIQTKVDS IAWKKLLPSQ 61 NGFHHILKWE NGSLPSNTSN DRFSFIVKNL SLLIKAAQQQ DSGLYCLEVT SISGKVQTAT 121 FQVFVFDKVE KPRLQGQGKI LDRGRCQVAL SCLVSRDGNV SYAWYRGSKL IQTAGNLTYL 181 DEEVDINGTH TYTCNVSNPV SWESHTLNLT QDCQNAHQEF RFWPFLVIIV ILSALFLGTL 241 ACFCVWRRKR KEKQSETSPK EFLTIYEDVK DLKTRRNHEQ EQTFPGGGST IYSMIQSQSS 301 APTSQEPAYT LYSLIQPSRK SGSRKRNHSP SFNSTIYEVI GKSQPKAQNP ARLSRKELEN 361 FDVYS*
Amino acid sequence in FASTA format (without gap)
CD244*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN, C-LIKE-DOMAIN
External links
Nomenclature
- HGNC: 18171
Genome databases
Sequence databases
- EMBL: AF105261, AF242540, AL354714, AF107761, AF117711, AJ245375, AF145782, BC053985, BC028073, AJ245377, AJ245376
- GenBank: AF105261, AF242540, AL354714, AF107761, AF117711, AJ245375, AF145782, BC053985, BC028073, AJ245377, AJ245376
- DDBJ: AF105261, AF242540, AL354714, AF107761, AF117711, AJ245375, AF145782, BC053985, BC028073, AJ245377, AJ245376
- TrEMBL: Q5VYI2, Q5VYI5, Q5VYI6
- NCBI: NM_016382, NP_057466
Structure databases
- PDB:
Created: 23/05/2007
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Romain Philippe, Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Romain Philippe, Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2025 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT