
IMGT Repertoire (RPI)
Other VSIG4 entries
- Mus musculus: VSIG4
IMGT RPI entry from gene to protein for Homo sapiens VSIG4
Citing IMGT RPI entry for VSIG4
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens VSIG4
- IMGT gene definition: V-set and immunoglobulin domain containing 4
Chromosomal localization
- Chromosome: X
- Chromosomal localization: Xq12-q13.3
Gene exon/intron organization
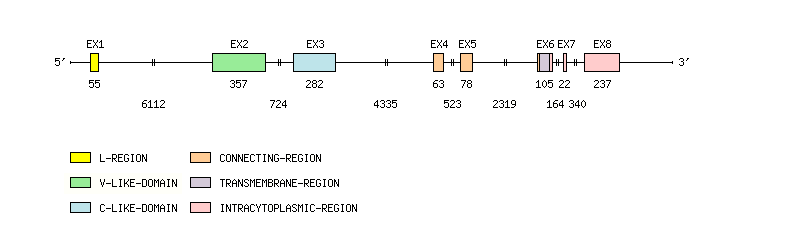
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 1
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| VSIG4*01 | F | EX1-8 | AJ132502[1] | cDNA |
IMGT reference sequences (in FASTA format) for the allele(s): VSIG4*01
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| VSIG4*01 | F | EX1-8 | AL034397 | gDNA |
| CQ789678 | gDNA | |||
| BC010525 | cDNA | |||
| EX1-7 | AY358341 | cDNA splicing B (1) | ||
| EX1-8 | NM_007268 | cDNA | ||
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| VSIG4*01 | AJ132502 | Q9Y279 | 399 aa | 1 |
| NM_007268 | NP_009199 | 399 aa | 1 | |
| AY358341 | 321 aa | 2 | ||
IMGT notes:
- (1) Splicing B (321 aa). No EX8.
IMGT references:
- [1] Langnaese K. et al., Biochim. Biophys. Acta 1492, 522-525 (2000). PMID:11004523
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
VSIG4*01: AJ132502(c) AL034397(g)
Nucleotide sequence
1 atggggatct tactgggcct gctactcctg gggcacctaa cagtggacac ttatggccgt 61 cccatcctgg aagtgccaga gagtgtaaca ggaccttgga aaggggatgt gaatcttccc 121 tgcacctatg accccctgca aggctacacc caagtcttgg tgaagtggct ggtacaacgt 181 ggctcagacc ctgtcaccat ctttctacgt gactcttctg gagaccatat ccagcaggca 241 aagtaccagg gccgcctgca tgtgagccac aaggttccag gagatgtatc cctccaattg 301 agcaccctgg agatggatga ccggagccac tacacgtgtg aagtcacctg gcagactcct 361 gatggcaacc aagtcgtgag agataagatt actgagctcc gtgtccagaa actctctgtc 421 tccaagccca cagtgacaac tggcagcggt tatggcttca cggtgcccca gggaatgagg 481 attagccttc aatgccaggc tcggggttct cctcccatca gttatatttg gtataagcaa 541 cagactaata accaggaacc catcaaagta gcaaccctaa gtaccttact cttcaagcct 601 gcggtgatag ccgactcagg ctcctatttc tgcactgcca agggccaggt tggctctgag 661 cagcacagcg acattgtgaa gtttgtggtc aaagactcct caaagctact caagaccaag 721 actgaggcac ctacaaccat gacatacccc ttgaaagcaa catctacagt gaagcagtcc 781 tgggactgga ccactgacat ggatggctac cttggagaga ccagtgctgg gccaggaaag 841 agcctgcctg tctttgccat catcctcatc atctccttgt gctgtatggt ggtttttacc 901 atggcctata tcatgctctg tcggaagaca tcccaacaag agcatgtcta cgaagcagcc 961 agggcacatg ccagagaggc caacgactct ggagaaacca tgagggtggc catcttcgca 1021 agtggctgct ccagtgatga gccaacttcc cagaatctgg gcaacaacta ctctgatgag 1081 ccctgcatag gacaggagta ccagatcatc gcccagatca atggcaacta cgcccgcctg 1141 ctggacacag ttcctctgga ttatgagttt ctggccactg agggcaaaag tgtctgttaa
Nucleotide sequence in FASTA format (without gaps)
VSIG4*01
Amino acid sequence
1 MGILLGLLLL GHLTVDTYGR PILEVPESVT GPWKGDVNLP CTYDPLQGYT QVLVKWLVQR 61 GSDPVTIFLR DSSGDHIQQA KYQGRLHVSH KVPGDVSLQL STLEMDDRSH YTCEVTWQTP 121 DGNQVVRDKI TELRVQKLSV SKPTVTTGSG YGFTVPQGMR ISLQCQARGS PPISYIWYKQ 181 QTNNQEPIKV ATLSTLLFKP AVIADSGSYF CTAKGQVGSE QHSDIVKFVV KDSSKLLKTK 241 TEAPTTMTYP LKATSTVKQS WDWTTDMDGY LGETSAGPGK SLPVFAIILI ISLCCMVVFT 301 MAYIMLCRKT SQQEHVYEAA RAHAREANDS GETMRVAIFA SGCSSDEPTS QNLGNNYSDE 361 PCIGQEYQII AQINGNYARL LDTVPLDYEF LATEGKSVC*
Amino acid sequence in FASTA format (without gap)
VSIG4*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN, C-LIKE-DOMAIN
IMGT databases
External links
Nomenclature
- HGNC: 17032
Genome database
Sequence database
- EMBL: AJ132502, AL034397, CQ789678, BC010525, AY358341
- GenBank: AJ132502, AL034397, CQ789678, BC010525, AY358341
- DDBJ: AJ132502, AL034397, CQ789678, BC010525, AY358341
- Swiss-Prot: Q9Y279
- TrEMBL:
- NCBI: NM_007268, NP_009199
Structure database
Created:
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2025 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT