
IMGT Repertoire (RPI)
Other B7 Family entries
IMGT RPI entry from gene to protein for Mus musculus B7A1
Citing IMGT RPI entry for B7A1
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Mus musculus B7A1
- IMGT gene definition: CD80 antigen
Chromosomal localization
- Chromosome: 16
- Chromosomal localization: 16 B5; 16 28.0 cM
Gene exon/intron organization
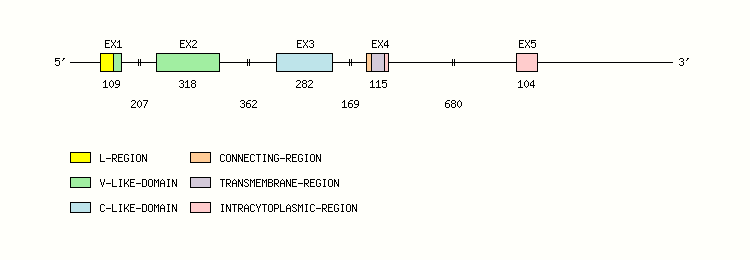
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 3
IMGT reference alleles
| Allele names | Gene functionality | Strains | IMGT reference sequences | ||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||
| B7A1*01 | F | EX1 | L12585 [1] | gDNA splicing A | |
| EX2 | L12586 | ||||
| EX3 | L12587 | ||||
| EX4 | L12588 | ||||
| EX5 | L12589 | ||||
| B7A1*02 | F | A/J | EX1-5 | AF065893 | cDNA splicing B (2) |
| B7A1*03 | F | C57BL/6CrSlc | EX1-2, EX4-5 | D16220 [3] | cDNA splicing C (3) |
IMGT reference sequences (in FASTA format) for the allele(s): B7A1*01 to B7A1*03
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | Strains | IMGT reference sequences | ||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||
| B7A1*01 | F | NOD | EX1-EX5 | AK154329[2] | cDNA splicing B |
| C57BL/6J | EX1-EX5 | AF065894 | |||
| B10.S/J | EX1-EX5 | AF065895 | |||
| SJL/J | EX1-EX5 | AF065896 | |||
| EX1-EX5 | AJ278965 | ||||
| EX1-EX5 | AY278186 | ||||
| EX1-EX5 | X60958 | ||||
| EX1-EX5 | NM_009855 | ||||
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| B7A1*01 | L12585 | Q00609 | 309 aa | 1 |
| L12586 | 309 aa | 1 | ||
| L12587 | 309 aa | 1 | ||
| L12588 | 309 aa | 1 | ||
| L12589 | 309 aa | 1 | ||
| NM_005191 | NP_005182 | 306 aa | 2 | |
| B7A1*02 | AF065893 | Tr:Q9R1Z9 | 306 aa | 2 |
| B7A1*03 | D16220 | 212 aa | 3 | |
IMGT notes:
- (1) Splicing B (306 aa). EX5 utilize the alternate splice site present 3 codons after the usual 5' splice site and the new amino acid G4>R is encoded by the alternative splicing. In EX3 [D2] a50>g, D17>G numbering according to unique numbering for C-LIKE-DOMAIN.
- (2) Splicing B (307 aa). EX5 utilize the alternate splice site present 3 codons after the usual 5' splice site and the new amino acid G4>R is encoded by the alternative splicing. In EX5 an insertion of a codon (aga) at position (49^>ins^aga, 7^>ins^R).
- (3) No EX3.
IMGT references:
- [1] Selvakumar.A, et al. Immunogenetics 36, 175-181 (1992). PMID:7686531
- [2] Carninci.P and Hayashizaki.Y., Meth. Enzymol. 303, 19-44 (1999). PMID:10349636
- [3] Inobe. M, et al. Biochem. Biophys. Res. Commun. 200, 443-449 (1994). PMID:7513163
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
B7A1*01: L12585(g) L12586(g) L12587(g) L12588(g) L12589(g)
Nucleotide sequence
1 atggcttgca attgtcagtt gatgcaggat acaccactcc tcaagtttcc atgtccaagg 61 ctcattcttc tctttgtgct gctgattcgt ctttcacaag tgtcttcaga tgttgatgaa 121 caactgtcca agtcagtgaa agataaggta ttgctgcctt gccgttacaa ctctcctcat 181 gaagatgagt ctgaagaccg aatctactgg caaaaacatg acaaagtggt gctgtctgtc 241 attgctggga aactaaaagt gtggcccgag tataagaacc ggactttata tgacaacact 301 acctactctc ttatcatcct gggcctggtc ctttcagacc ggggcacata cagctgtgtc 361 gttcaaaaga aggaaagagg aacgtatgaa gttaaacact tggctttagt aaagttgtcc 421 atcaaagctg acttctctac ccccaacata actgagtctg gaaacccatc tgcagacact 481 aaaaggatta cctgctttgc ttccgggggt ttcccaaagc ctcgcttctc ttggttggaa 541 aatggaagag aattacctgg catcaatacg acaatttccc aggatcctga atctgaattg 601 tacaccatta gtagccaact agatttcaat acgactcgca accacaccat taagtgtctc 661 attaaatatg gagatgctca cgtgtcagag gacttcacct gggaaaaacc cccagaagac 721 cctcctgata gcaagaacac acttgtgctc tttggggcag gattcggcgc agtaataaca 781 gtcgtcgtca tcgttgtcat catcaaatgc ttctgtaagc acaatcttca aggaagctgt 841 ttcagaagaa atgaggcaag cagagaaaca aacaacagcc ttaccttcgg gcctgaagaa 901 gcattagctg aacagaccgt cttcctttag
Nucleotide sequence in FASTA format (without gaps)
B7A1*01
Amino acid sequence
1 MACNCQLMQD TPLLKFPCPR LILLFVLLIR LSQVSSDVDE QLSKSVKDKV LLPCRYNSPH 61 EDESEDRIYW QKHDKVVLSV IAGKLKVWPE YKNRTLYDNT TYSLIILGLV LSDRGTYSCV 121 VQKKERGTYE VKHLALVKLS IKADFSTPNI TESGNPSADT KRITCFASGG FPKPRFSWLE 181 NGRELPGINT TISQDPESEL YTISSQLDFN TTRNHTIKCL IKYGDAHVSE DFTWEKPPED 241 PPDSKNTLVL FGAGFGAVIT VVVIVVIIKC FCKHNLQGSC FRRNEASRET NNSLTFGPEE 301 ALAEQTVFL*
Amino acid sequence in FASTA format (without gap)
B7A1*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT RepertoireChromosomal localization
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN, C-LIKE-DOMAIN
External links
Nomenclature
- HGNC:
Genome databases
Sequence database
- EMBL: L12585, L12586, L12587, L12588, L12589, AF065893, D16220, AK154329, AF065894, AF065895, AF065896, AJ278965
- GenBank: L12585, L12586, L12587, L12588, L12589, AF065893, D16220, AK154329, AF065894, AF065895, AF065896, AJ278965
- DDBJ: L12585, L12586, L12587, L12588, L12589, AF065893, D16220, AK154329, AF065894, AF065895, AF065896, AJ278965
- Swiss-Prot: Q00609
- TrEMBL: Q3U4B5, Q549R2, Q6LD87, Q99JC4, Q9JHC3, Q9R1Z9
- NCBI: NM_009855, NP_033985
Structure database
- PDB:
Created: 23/05/2007
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2025 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT