
IMGT Repertoire (RPI)
Other CD4 entries
- Homo sapiens: CD4
IMGT RPI entry from gene to protein for Mus musculus CD4
Citing IMGT RPI entry for CD4
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Mus musculus CD4
- IMGT gene definition: CD4 antigen (p55)
Chromosomal localization
- Chromosome: 6
- Chromosomal localization: 6F2; 6 60.18 cM
Gene exon/intron organization
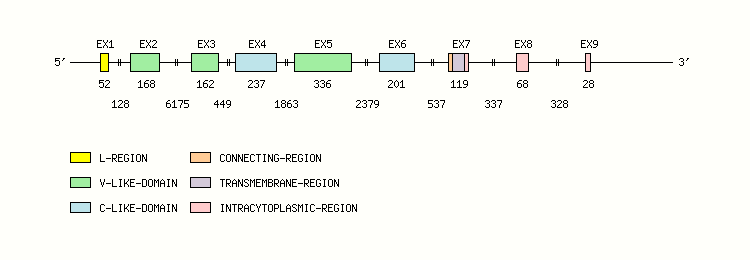
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 2
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| CD4*01 | F | EX1-2 | M17076 [1] | gDNA |
| EX3-4 | M17077 | gDNA | ||
| EX5 | M17078 | gDNA | ||
| EX6 | M17079 | gDNA | ||
| EX7-9 | M17080 | gDNA | ||
| CD4*02 | F | EX1-9 | AC002397 | gDNA (1) |
IMGT reference sequences (in FASTA format) for the allele(s): CD4*01 to CD4*02
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | Strains | IMGT reference sequences | ||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||
| CD4*01 | C57BL/cDJ | EX5-6, 8 | U75219 | cDNA partial (2)splicing B | |
| CD4*02 | F | EX1-9 | AF045882 | gDNA | |
| NOD | EX1-9 | AK153966 | cDNA | ||
| C57BL/6J | EX1-9 | AK161775 | |||
| EX1-9 | BC039137 | ||||
| EX1-9 | M36850 | ||||
| EX1-9 | X04836 | ||||
| EX1-9 | M13816 | ||||
| EX1-9 | NM_013488 | ||||
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| CD4*01 | M17076 | 457 aa | 1 | |
| M17077 | 457 aa | 1 | ||
| M17078 | 457 aa | 1 | ||
| M17079 | 457 aa | 1 | ||
| M17080 | 457 aa | 1 | ||
| CD4*02 | AC002397 | P06332 | 457 aa | 1 |
| NM_013488 | NP_038516 | 457 aa | 1 | |
IMGT notes:
- (1) In EX2 [D1] a20>g; E7>G, numbering according to IMGT unique numbering for V-LIKE-DOMAIN.
- (2) Partial. Splicing B. No EX7. Skipping of EX7 cause the frame shift and the translation ends with in EX8.
IMGT references:
- [1] Gorman S.D, Tourvieille. B. and Parnes J.R. Proc. Natl. Acad. Sci. U.S.A. 84, 7644-7648 (1987). PMID:2823269
- [2] Ansari-Lari. M.A. et al, Genome Res. 8, 29-40 (1998). PMID:9445485
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
CD4*01: M17076(g) M17077(g) M17078(g) M17079(g) M17080(g)
Nucleotide sequence
1 atgtgccgag ccatctctct taggcgcttg ctgctgctgc tgctgcagct gtcacaactc 61 ctagctgtca ctcaagagaa gacgctggtg ctggggaagg aaggggaatc agcagaactg 121 ccctgcgaga gttcccagaa gaagatcaca gtcttcacct ggaagttctc tgaccagagg 181 aagattctgg ggcagcatgg caaaggtgta ttaattagag gaggttcgcc ttcgcagttt 241 gatcgttttg attccaaaaa aggggcatgg gagaaaggat cgtttcctct catcatcaat 301 aaacttaaga tggaagactc tcagacttat atctgtgagc tggagaacag gaaagaggag 361 gtggagttgt gggtgttcaa agtgaccttc agtccgggta ccagcctgtt gcaagggcag 421 agcctgaccc tgaccttgga tagcaactct aaggtctcta accccttgac agagtgcaaa 481 cacaaaaagg gtaaagttgt cagtggttcc aaagttctct ccatgtccaa cctaagggtt 541 caggacagcg acttctggaa ctgcaccgtg accctggacc agaaaaagaa ctggttcggc 601 atgacactct cagtgctggg ttttcagagc acagctatca cggcctataa gagtgaggga 661 gagtcagcgg agttctcctt cccactcaac tttgcagagg aaaacgggtg gggagagctg 721 atgtggaagg cagagaagga ttctttcttc cagccctgga tctccttctc cataaagaac 781 aaagaggtgt ccgtacaaaa gtccaccaaa gacctcaagc tccagctgaa ggaaacgctc 841 ccactcaccc tcaagatacc ccaggtctcg cttcagtttg ctggttctgg caacctgact 901 ctgactctgg acaaagggac actgcatcag gaagtgaacc tggtggtgat gaaagtggct 961 cagctcaaca atactttgac ctgtgaggtg atgggaccta cctctcccaa gatgagactg 1021 accctgaagc aggagaacca ggaggccagg gtctctgagg agcagaaagt agttcaagtg 1081 gtggcccctg agacagggct gtggcagtgt ctactgagtg aaggtgataa ggtcaagatg 1141 gactccagga tccaggtttt atccagaggg gtgaaccaga cagtgttcct ggcttgcgtg 1201 ctgggtggct ccttcggctt tctgggtttc cttgggctct gcatcctctg ctgtgtcagg 1261 tgccggcacc aacagcgcca ggcagcacga atgtctcaga tcaagaggct cctcagtgag 1321 aagaagacct gccagtgccc ccaccggatg cagaagagcc ataatctcat ctga
Nucleotide sequence in FASTA format (without gaps)
CD4*01
Amino acid sequence
1 MCRAISLRRL LLLLLQLSQL LAVTQEKTLV LGKEGESAEL PCESSQKKIT VFTWKFSDQR 61 KILGQHGKGV LIRGGSPSQF DRFDSKKGAW EKGSFPLIIN KLKMEDSQTY ICELENRKEE 121 VELWVFKVTF SPGTSLLQGQ SLTLTLDSNS KVSNPLTECK HKKGKVVSGS KVLSMSNLRV 181 QDSDFWNCTV TLDQKKNWFG MTLSVLGFQS TAITAYKSEG ESAEFSFPLN FAEENGWGEL 241 MWKAEKDSFF QPWISFSIKN KEVSVQKSTK DLKLQLKETL PLTLKIPQVS LQFAGSGNLT 301 LTLDKGTLHQ EVNLVVMKVA QLNNTLTCEV MGPTSPKMRL TLKQENQEAR VSEEQKVVQV 361 VAPETGLWQC LLSEGDKVKM DSRIQVLSRG VNQTVFLACV LGGSFGFLGF LGLCILCCVR 421 CRHQQRQAAR MSQIKRLLSE KKTCQCPHRM QKSHNLI*
Amino acid sequence in FASTA format (without gap)
CD4*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN, C-LIKE-DOMAIN, V-LIKE-DOMAIN, C-LIKE-DOMAIN
External links
Nomenclature
- HGNC:
Genome databases
Sequence databases
- EMBL: M17076, M17077, M17078, M17079, M17080, AC002397, U75219, AF045882, AK153966, AK161775, BC039137, M36850, X04836, M13816
- GenBank: M17076, M17077, M17078, M17079, M17080, AC002397, U75219, AF045882, AK153966, AK161775, BC039137, M36850, X04836, M13816
- DDBJ: M17076, M17077, M17078, M17079, M17080, AC002397, U75219, AF045882, AK153966, AK161775, BC039137, M36850, X04836, M13816
- Swiss-Prot: P06332
- TrEMBL:
- NCBI: NM_013488, NP_038516
Structure database
- PDB:
Created: 23/05/2007
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2025 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT