
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Homo sapiens B2M
Citing IMGT RPI entry for B2M
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens B2M
- IMGT gene definition: beta-2-microglobulin
Chromosomal localization
- Chromosome: 15
- Chromosomal localization: 15q21.1
Gene exon/intron organization
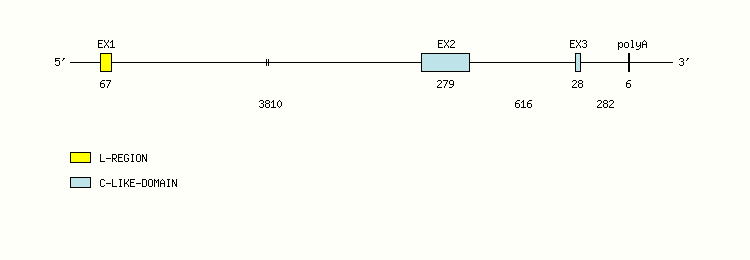
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 2
IMGT reference alleles
| Allele name | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Clone names | Accession numbers | Molecule type | ||
| B2M*01 (1) | F | AB021288 | cDNA (2) | |
| B2M*02 (1) | F | EX1 : M17986 | gDNA | |
| EX2-EX3 : M17987 | ||||
IMGT reference sequences (in FASTA format) for the allele(s): B2M*01 (1) to B2M*02 (1)
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele name | Gene functionality | IMGT sequences from the literature | ||
|---|---|---|---|---|
| Clone names | Accession numbers | Molecule type | ||
| B2M*01 | F | AF072097 | cDNA | |
| NM_004048 | cDNA | |||
| BC032589 | cDNA | |||
| CR457066 | cDNA | |||
| BC064910 | cDNA | |||
Corresponding protein database accession numbers
| Allele name | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| B2M*01 | AB021288 | P61769 | 119 aa | |
| B2M*02 | EX1 : M17986 | 119 aa | ||
| EX2-EX3 : M17987 | ||||
IMGT notes:
- (1) The two alleles differ by two nucleotides in EX1 (c59>g, t60>c, A20>G) and one nucleotide in EX2. c155>a (corresponding to c89>a, P30>Q in the IMGT unique numbering for C-DOMAIN and C-LIKE-DOMAIN).
- (2) Wrongly described as gDNA in the flat file.
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
B2M*01: AB021288(c)
Nucleotide sequence
1 atgtctcgct ccgtggcctt agctgtgctc gcgctactct ctctttctgg cctggaggct 61 atccagcgta ctccaaagat tcaggtttac tcacgtcatc cagcagagaa tggaaagtca 121 aatttcctga attgctatgt gtctgggttt catccatccg acattgaagt tgacttactg 181 aagaatggag agagaattga aaaagtggag cattcagact tgtctttcag caaggactgg 241 tctttctatc tcttgtacta cactgaattc acccccactg aaaaagatga gtatgcctgc 301 cgtgtgaacc atgtgacttt gtcacagccc aagatagtta agtgggatcg agacatgtaa
Nucleotide sequence in FASTA format (without gaps)
B2M*01
Amino acid sequence
1 MSRSVALAVL ALLSLSGLEA IQRTPKIQVY SRHPAENGKS NFLNCYVSGF HPSDIEVDLL 61 KNGERIEKVE HSDLSFSKDW SFYLLYYTEF TPTEKDEYAC RVNHVTLSQP KIVKWDRDM*
Amino acid sequence in FASTA format (without gap)
B2M*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays: C-LIKE-DOMAIN
- IMGT Collier de perles: C-LIKE-DOMAIN
IMGT databases
- IMGT/3Dstructure-DB: 2F8O
External links
Nomenclature
- HGNC: 914
Genome databases
Sequence databases
Structure database
- PDB: 1AKJ
Created: 10/11/2005
Last updated: 02/10/2025 15:10
Authors: Lamia Zaghloul, Fatena Bellahcene
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Lamia Zaghloul, Fatena Bellahcene
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT