
IMGT Repertoire (RPI)
Other CD1 entries
- Homo sapiens: CD1A
IMGT RPI entry from gene to protein for Homo sapiens CD1C
IMGT gene name and definition
- IMGT gene name: Homo sapiens CD1C
- IMGT gene definition: CD1C antigen, c polypeptide
Chromosomal localization
- Chromosome: 1
- Chromosomal localization: 1q22-q23
Gene exon/intron organization
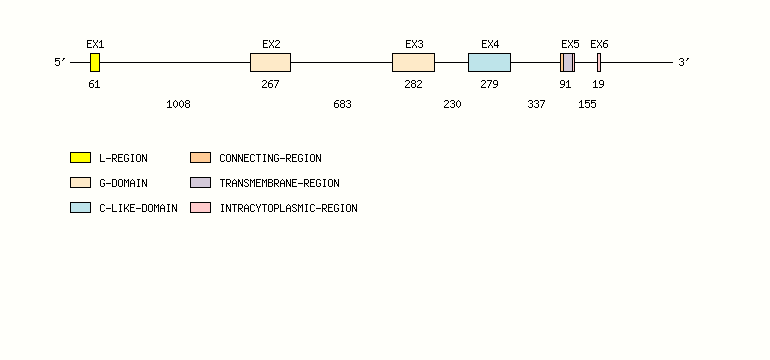
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 5
IMGT reference alleles
| Allele name | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Clone names | Accession numbers | Molecule type | ||
| CD1C*01 | F | AL121986 | gDNA | |
| CD1C*02 | F | M22827 | cDNA | |
| CD1C*03 | F | lambda-R7L4 | M22174 | gDNA (EX1) |
| M22175 | gDNA (EX2) | |||
| M22176 | gDNA (EX3) | |||
| M22177 | gDNA (EX4) | |||
| M22178 | gDNA (EX5) | |||
| CD1C*04 | F | AF142667 | gDNA (1) | |
| CD1C*05 | F | RZPDo834E0711D | CR457050 | cDNA |
IMGT reference sequences (in FASTA format) for the allele(s): CD1C*01 to CD1C*05
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Corresponding protein database accession numbers
| Allele name | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| CD1C*01 | AL121986 | 333 aa | ||
| CD1C*02 | NM_001765 | NP_001756 | 333 aa | |
| M22827 | Sw: P29017 | 327 aa | ||
| CD1C*03 | M22174 to M22178 | 326 aa | ||
| CD1C*04 | AF142667 (1) | 91 aa | ||
| CD1C*05 | CR47050 | CAG33361 | 333 aa | |
IMGT notes:
- (1) partial cds, only EX2
Genomic sequence
Position: 16490...19901 (from ATG to stop codon included).Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
CD1C*01: AL121986(g)
Nucleotide sequence
1 atgctgtttc tgcagtttct gctgctagct cttcttctcc caggtggtga caatgcagac 61 gcatcccagg aacacgtctc cttccatgtc atccagatct tctcatttgt caaccaatcc 121 tgggcacgag gtcagggctc aggatggctg gacgagttgc agactcatgg ctgggacagt 181 gaatcaggca caataatttt cctgcataac tggtccaagg gcaacttcag caatgaagag 241 ttgtcagacc tagagttgtt atttcgtttc tacctctttg gattaactcg ggagattcaa 301 gaccatgcaa gtcaagatta ctcgaaatat ccctttgaag tacaggtgaa agcgggctgt 361 gagctgcatt ctggaaagag cccagaaggc ttctttcagg tagctttcaa cggattagat 421 ttactgagtt tccagaatac aacatgggtg ccatctccag gctgtggaag tttggcccaa 481 agtgtctgtc atctactcaa tcatcagtat gaaggcgtca cagaaacagt gtataatctc 541 ataagaagca cttgcccccg atttctcttg ggtctcctgg atgcagggaa gatgtatgta 601 cacaggcaag tgaggccaga agcctggctg tccagtcgcc ccagccttgg gtctggccag 661 ctgttgctgg tttgtcatgc ctccggcttc tacccaaagc ctgtttgggt gacatggatg 721 cggaatgaac aggagcaact gggcactaaa catggtgata ttcttcctaa tgctgatggg 781 acatggtatc ttcaggtgat cctggaggtg gcatctgagg agcctgctgg cctgtcttgt 841 cgagtgagac acagcagtct aggaggccag gacatcatcc tctactgggg acaccacttt 901 tccatgaatt ggattgcctt ggtagtgata gtgcccttgg tgattctaat agtccttgtg 961 ttatggttta agaagcactg ctcatatcag gacatcctgt ga
Nucleotide sequence in FASTA format (without gaps)
CD1C*01
Amino acid sequence
1 MLFLQFLLLA LLLPGGDNAD ASQEHVSFHV IQIFSFVNQS WARGQGSGWL DELQTHGWDS 61 ESGTIIFLHN WSKGNFSNEE LSDLELLFRF YLFGLTREIQ DHASQDYSKY PFEVQVKAGC 121 ELHSGKSPEG FFQVAFNGLD LLSFQNTTWV PSPGCGSLAQ SVCHLLNHQY EGVTETVYNL 181 IRSTCPRFLL GLLDAGKMYV HRQVRPEAWL SSRPSLGSGQ LLLVCHASGF YPKPVWVTWM 241 RNEQEQLGTK HGDILPNADG TWYLQVILEV ASEEPAGLSC RVRHSSLGGQ DIILYWGHHF 301 SMNWIALVVI VPLVILIVLV LWFKKHCSYQ DIL*
Amino acid sequence in FASTA format (without gap)
CD1C*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays (MHC): G-LIKE-ALPHA1 [D1]
- IMGT Collier de perles: G-LIKE-DOMAINs
- HGNC: 1636
- Entrez Gene: 911
- GENATLAS: 76
- GeneCards: GC01P155476
- GDB: GDB:1010998
- OMIM: 188340
External links
Nomenclature
Genome databases
Sequence databases
Created: 18/10/2006
Last updated: 02/10/2025 15:10
Authors: Sandra Ghayad
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Sandra Ghayad
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT