
IMGT Repertoire (RPI)
Other CD1 entries
- Homo sapiens: CD1A
IMGT RPI entry from gene to protein for Homo sapiens CD1D
IMGT gene name and definition
- IMGT gene name: Homo sapiens CD1D
- IMGT gene definition: CD1D antigen, d polypeptide
Chromosomal localization
- Chromosome: 1
- Chromosomal localization: 1q22-q23
Gene exon/intron organization
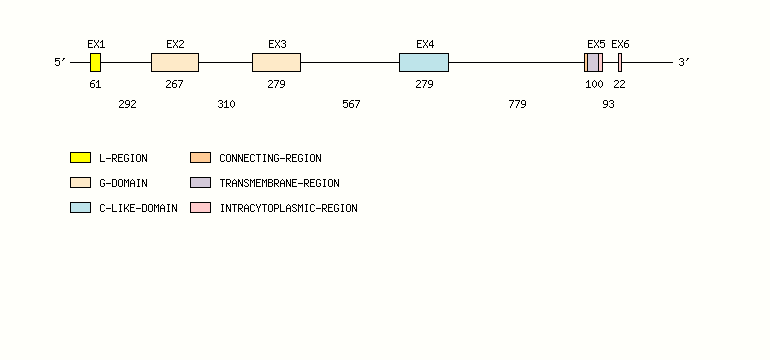
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Gene table (Locus and genes)
Corresponding protein database accession numbers
| Allele names | IMGT/LIGM-DB | UniProt | Protein isoform | ||
|---|---|---|---|---|---|
| Accession numbers | Sequence lengths (nt) | Accession numbers | Sequence lengths (AA) | ||
| CD1D*01 | AL138899 | 1005 | P15813 | 335 | |
| X14974 | P15813 | 335 | |||
| L38815 to L38820 | P15813 | 352 | |||
| J04142 | P15813 | 335 | |||
| BC027926 | P15813 | 335 | |||
| AP002532 | P15813 | 335 | |||
| AK225996 | 726 | 242 | |||
| CD1D*02 | AF142668 | 266 | P15813 | 88 | |
| CD1D*03 | KF742502 | 213 | 70 | ||
| CD1D*04 | KF751734 | 213 | 70 | ||
Genomic sequence
Position (2): 19674 ... 19990 (ATG and EX1), 1 ... 2792 (EX2 to stop codon included) (2).Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
CD1C*01: AL138899(g)
Nucleotide sequence
1 atggggtgcc tgctgtttct gctgctctgg gcgctcctcc aggcttgggg aagcgctgaa 61 gtcccgcaaa ggcttttccc cctccgctgc ctccagatct cgtccttcgc caatagcagc 121 tggacgcgca ccgacggctt ggcgtggctg ggggagctgc agacgcacag ctggagcaac 181 gactcggaca ccgtccgctc tctgaagcct tggtcccagg gcacgttcag cgaccagcag 241 tgggagacgc tgcagcatat atttcgggtt tatcgaagca gcttcaccag ggacgtgaag 301 gaattcgcca aaatgctacg cttatcctat cccttggagc tccaggtgtc cgctggctgt 361 gaggtgcacc ctgggaacgc ctcaaataac ttcttccatg tagcatttca aggaaaagat 421 atcctgagtt tccaaggaac ttcttgggag ccaacccaag aggccccact ttgggtaaac 481 ttggccattc aagtgctcaa ccaggacaag tggacgaggg aaacagtgca gtggctcctt 541 aatggcacct gcccccaatt tgtcagtggc ctccttgagt cagggaagtc ggaactgaag 601 aagcaagtga agcccaaggc ctggctgtcc cgtggcccca gtcctggccc tggccgtctg 661 ctgctggtgt gccatgtctc aggattctac ccaaagcctg tatgggtgaa gtggatgcgg 721 ggtgagcagg agcagcaggg cactcagcca ggggacatcc tgcccaatgc tgacgagaca 781 tggtatctcc gagcaaccct ggatgtggtg gctggggagg cagctggcct gtcctgtcgg 841 gtgaagcaca gcagtctaga gggccaggac atcgtcctct actggggtgg gagctacacc 901 tccatgggct tgattgcctt ggcagtcctg gcgtgcttgc tgttcctcct cattgtgggc 961 tttacctccc ggtttaagag gcaaacttcc tatcagggcg tcctgtga
Nucleotide sequence in FASTA format (without gaps)
CD1D*01
Amino acid sequence
1 MGCLLFLLLW ALLQAWGSAE VPQRLFPLRC LQISSFANSS WTRTDGLAWL GELQTHSWSN 61 DSDTVRSLKP WSQGTFSDQQ WETLQHIFRV YRSSFTRDVK EFAKMLRLSY PLELQVSAGC 121 EVHPGNASNN FFHVAFQGKD ILSFQGTSWE PTQEAPLWVN LAIQVLNQDK WTRETVQWLL 181 NGTCPQFVSG LLESGKSELK KQVKPKAWLS RGPSPGPGRL LLVCHVSGFY PKPVWVKWMR 241 GEQEQQGTQP GDILPNADET WYLRATLDVV AGEAAGLSCR VKHSSLEGQD IVLYWGGSYT 301 SMGLIALAVL ACLLFLLIVG FTSRFKRQTS YQGVL*
Amino acid sequence in FASTA format (without gap)
CD1D*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays (MHC): G-LIKE-ALPHA1 [D1]
- IMGT Collier de perles: G-LIKE-DOMAINs
External links
Nomenclature
- HGNC: 1637
Genome databases
- Entrez Gene: 912
- GENATLAS: 77
- GeneCards: GC01P155366
- GDB: 1010996
- OMIM: 188410
Sequence databases
Created: 18/10/2006
Last updated: 02/10/2025 15:10
Authors: Sandra Ghayad
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Sandra Ghayad
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT