
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Mus musculus CD28
Citing IMGT RPI entry for CD28
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Mus musculus CD28
- IMGT gene definition: CD28 antigen (Tp44)
Chromosomal localization
- Chromosome: 1
- Chromosomal localization: 1 C1-C3;30.1cM
Gene exon/intron organization
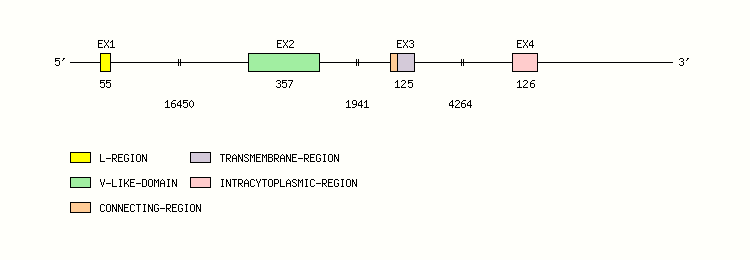
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 1
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | |||
|---|---|---|---|---|---|
| Clone names | Exons | Accession numbers | Molecule type | ||
| CD28*01 | F | EX1-4 | AL672024 | gDNA | |
IMGT reference sequences (in FASTA format) for the allele(s): CD28*01
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | |||
|---|---|---|---|---|---|
| Clone names | Exons | Accession numbers | Molecule type | ||
| CD28*01 | F | RP23-157N11 | EX1-4 | AL646054 | gDNA |
| DN-378G17 | EX1-4 | M34563[1] | cDNA(1) | ||
| 5830411K06 | EX1-4 | AK030812 | cDNA | ||
| MGC:73611 | EX1-4 | BC064058 | |||
| EX1-4 | NM_007642 | ||||
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| CD28*01 | AL672024 | P09693 | 218 aa | 1 |
| NM_007642 | NP_031668 | 218 aa | 1 | |
| CD28*02 | M34563 | P31041 | 218 aa | 1 |
IMGT notes:
- (1) In EX4, sequence from 34-41[agtgacta]>[gtgactac], 12-14[SDY]>[VTT].
IMGT references:
- [1] Gross, J.A., St John, T. and Allison, J.P. Journal of Immunology 144, 3201-3210 (1990). PMID:2157764
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
CD28*01: AL672024(g)
Nucleotide sequence
1 atgacactca ggctgctgtt cttggctctc aacttcttct cagttcaagt aacagaaaac 61 aagattttgg taaagcagtc gcccctgctt gtggtagata gcaacgaggt cagcctcagc 121 tgcaggtatt cctacaacct tctcgcaaag gaattccggg catccctgta caagggcgtg 181 aacagcgacg tggaagtctg tgtcgggaat gggaatttta cctatcagcc ccagtttcgc 241 tcgaatgccg agttcaactg cgacggggat ttcgacaacg aaacagtgac gttccgtctc 301 tggaatctgc acgtcaatca cacagatatt tacttctgca aaattgagtt catgtaccct 361 ccgccttacc tagacaacga gaggagcaat ggaactatta ttcacataaa agagaaacat 421 ctttgtcata ctcagtcatc tcctaagctg ttttgggcac tggtcgtggt tgctggagtc 481 ctgttttgtt atggcttgct agtgacagtg gctctttgtg ttatctggac aaatagtaga 541 aggaacagac tccttcaaag tgactacatg aacatgactc cccggaggcc tgggctcact 601 cgaaagcctt accagcccta cgcccctgcc agagactttg cagcgtaccg cccctga
Nucleotide sequence in FASTA format (without gaps)
CD28*01
Amino acid sequence
1 MTLRLLFLAL NFFSVQVTEN KILVKQSPLL VVDSNEVSLS CRYSYNLLAK EFRASLYKGV 61 NSDVEVCVGN GNFTYQPQFR SNAEFNCDGD FDNETVTFRL WNLHVNHTDI YFCKIEFMYP 121 PPYLDNERSN GTIIHIKEKH LCHTQSSPKL FWALVVVAGV LFCYGLLVTV ALCVIWTNSR 181 RNRLLQSDYM NMTPRRPGLT RKPYQPYAPA RDFAAYRP*
Amino acid sequence in FASTA format (without gap)
CD28*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT RepertoireChromosomal localization
- Alignment of alleles:
- Protein displays: V-LIKE-DOMAINs
- IMGT Collier de perles: V-LIKE-DOMAIN
External links
Nomenclature
- MGDsearch: 88327
Genome databases
- Entrez Gene: 12487
- GENATLAS:
- GeneCards:
- GDB:
- OMIM:
Sequence databases
Structure database
- PDB:
Created: 27/11/06
Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT