
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Homo sapiens CTLA4
Citing IMGT RPI entry for CTLA4
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens CTLA4
- IMGT gene definition: cytotoxic T-lymphocyte-associated protein 4
Chromosomal localization
- Chromosome: 2
- Chromosomal localization: 2q33
Gene exon/intron organization
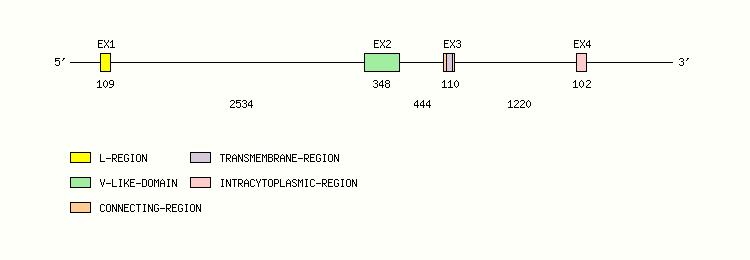
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 3
IMGT reference alleles
| Allele names | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | ||
| CTLA4*01 | F | EX1 | M74363 [1] | gDNA |
| EX2-4 | M37243-M37245 | cDNA | ||
| CTLA4*02 | F | EX1-4 | AC010138 | cDNA (1) |
| CTLA4*03 | F | EX1-4 | AF411058 [2] | cDNA (2) |
IMGT reference sequences (in FASTA format) for the allele(s): CTLA4*01 to CTLA4*03
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | IMGT reference sequences | |||
|---|---|---|---|---|---|
| Clones | Exons | Accession numbers | Molecule type | ||
| CTLA4*02 | F | EX1-4 | AF414120 | cDNA | |
| MGC:104099 | EX1-4 | BC074842 | |||
| MGC:103840 | EX1-4 | BC074843 | |||
| EX1-4 | NM_005214 | ||||
| CTLA4*03 | F | EX1-4 | AY209009 | cDNA | |
| MGC:97034 | EX1-4 | BC069566 | |||
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| CTLA4*01 | M37243 | 223 aa | 1 | |
| CTLA4*02 | AC010138 | P16410 | 223 aa | 1 |
| NM_005214 | NP_005205 | 223 aa | 1 | |
| CTLA4*03 | AF411058 | 223 aa | 1 | |
IMGT notes:
- (1) EX2[D] 332g>a; 122A>T numbering according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN.
- (2) In EX1 49a>g, 17T>A this mutation has been linked to autoimmune diseases such as Graves' disease and type 1 diabetes and EX2[D] 332g>a; 122A>T numbering according to IMGT unique numbering for V-DOMAIN and V-LIKE-DOMAIN.
IMGT references:
- [1] Dariavach, P., Mattei,M.G., Golstein,P. and Lefranc,M.P. Eur. J. Immunol. 18, 1901-1905 (1988). PMID:3220103
- [2] Ling,V., Wu,P.W. et al. Genomics 78, 155-168 (2001). PMID:11735222
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
CTLA4*01: M74363(g)
Nucleotide sequence
1 atggcttgcc ttggatttca gcggcacaag gctcagctga acctggctac caggacctgg 61 ccctgcactc tcctgttttt tcttctcttc atccctgtct tctgcaaagc aatgcacgtg 121 gcccagcctg ctgtggtact ggccagcagc cgaggcatcg ccagctttgt gtgtgagtat 181 gcatctccag gcaaagccac tgaggtccgg gtgacagtgc ttcggcaggc tgacagccag 241 gtgactgaag tctgtgcggc aacctacatg atggggaatg agttgacctt cctagatgat 301 tccatctgca cgggcacctc cagtggaaat caagtgaacc tcactatcca aggactgagg 361 gccatggaca cgggactcta catctgcaag gtggagctca tgtacccacc gccatactac 421 ctgggcatag gcaacggagc ccagatttat gtaattgatc cagaaccgtg cccagattct 481 gacttcctcc tctggatcct tgcagcagtt agttcggggt tgttttttta tagctttctc 541 ctcacagctg tttctttgag caaaatgcta aagaaaagaa gccctcttac aacaggggtc 601 tatgtgaaaa tgcccccaac agagccagaa tgtgaaaagc aatttcagcc ttattttatt 661 cccatcaatt ga
Nucleotide sequence in FASTA format (without gaps)
CTLA4*01
Amino acid sequence
1 MACLGFQRHK AQLNLATRTW PCTLLFFLLF IPVFCKAMHV AQPAVVLASS RGIASFVCEY 61 ASPGKATEVR VTVLRQADSQ VTEVCAATYM MGNELTFLDD SICTGTSSGN QVNLTIQGLR 121 AMDTGLYICK VELMYPPPYY LGIGNGAQIY VIDPEPCPDS DFLLWILAAV SSGLFFYSFL 181 LTAVSLSKML KKRSPLTTGV YVKMPPTEPE CEKQFQPYFI PIN*
Amino acid sequence in FASTA format (without gap)
CTLA4*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays: V-LIKE-DOMAINs
- IMGT Collier de perles: V-LIKE-DOMAIN
IMGT databases
Created: 27/11/2006
Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT