
IMGT Repertoire (RPI)
Other MIC entries
- Homo sapiens: MICA
IMGT RPI entry from gene to protein for Homo sapiens MICB
IMGT gene name and definition
- IMGT gene name: Homo sapiens MICB
- IMGT gene definition: RPI-MH1Like MICB
Chromosomal localization
- Chromosome: 6
- Chromosomal localization: 6p21.33
Gene exon/intron organization
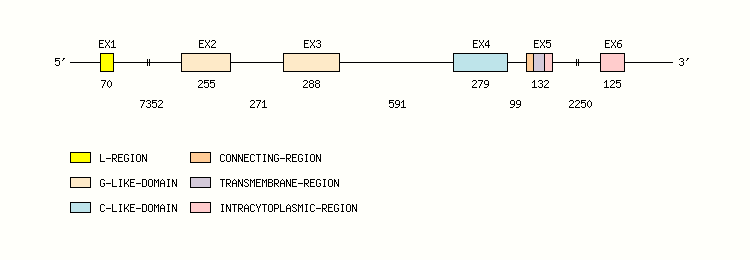
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Gene table (Locus and genes)
Corresponding protein database accession numbers
| Allele name | Accession numbers | Number of amino acids (1) | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases (2) | |||
| MICB*02 | X91625 | Tr: Q29980 | 383 aa | |
IMGT notes:
- (1) Many TREMBL entries but no SWISS-PROT entry (13/06/2005). For retrieval of TREMBL entries, search ExPASy server with EMBL accession numbers (tables above).
- (2) including the L-REGION
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
MICB*01: AL663061(g)
Nucleotide sequence
1 atggggctgg gccgggtcct gctgtttctg gccgtcgcct tcccttttgc acccccggca 61 gccgccgctg agccccacag tcttcgttac aacctcatgg tgctgtccca ggatggatct 121 gtgcagtcag ggtttctcgc tgagggacat ctggatggtc agcccttcct gcgctatgac 181 aggcagaaac gcagggcaaa gccccaggga cagtgggcag aaaatgtcct gggagctaag 241 acctgggaca cagagaccga ggacttgaca gagaatgggc aagacctcag gaggaccctg 301 actcatatca aggaccagaa aggaggcttg cattccctcc aggagattag ggtctgtgag 361 atccatgaag acagcagcac caggggctcc cggcatttct actacgatgg ggagctcttc 421 ctctcccaaa acctggagac tcaagaatcg acagtgcccc agtcctccag agctcagacc 481 ttggctatga acgtcacaaa tttctggaag gaagatgcca tgaagaccaa gacacactat 541 cgcgctatgc aggcagactg cctgcagaaa ctacagcgat atctgaaatc cggggtggcc 601 atcaggagaa cagtgccccc catggtgaat gtcacctgca gcgaggtctc agagggcaac 661 atcaccgtga catgcagggc ttccagcttc tatccccgga atatcacact gacctggcgt 721 caggatgggg tatctttgag ccacaacacc cagcagtggg gggatgtcct gcctgatggg 781 aatggaacct accagacctg ggtggccacc aggattcgcc aaggagagga gcagaggttc 841 acctgctaca tggaacacag cgggaatcac ggcactcacc ctgtgccctc tgggaaggcg 901 ctggtgcttc agagtcaacg gacagacttt ccatatgttt ctgctgctat gccatgtttt 961 gttattatta ttattctctg tgtcccttgt tgcaagaaga aaacatcagc ggcagagggt 1021 ccagagcttg tgagcctgca ggtcctggat caacacccag ttgggacagg agaccacagg 1081 gatgcagcac agctgggatt tcagcctctg atgtcagcta ctgggtccac tggttccact 1141 gagggcacct ag
Nucleotide sequence in FASTA format (without gaps)
MICB*01
Amino acid sequence
1 MGLGRVLLFL AVAFPFAPPA AAAEPHSLRY NLMVLSQDGS VQSGFLAEGH LDGQPFLRYD 61 RQKRRAKPQG QWAENVLGAK TWDTETEDLT ENGQDLRRTL THIKDQKGGL HSLQEIRVCE 121 IHEDSSTRGS RHFYYDGELF LSQNLETQES TVPQSSRAQT LAMNVTNFWK EDAMKTKTHY 181 RAMQADCLQK LQRYLKSGVA IRRTVPPMVN VTCSEVSEGN ITVTCRASSF YPRNITLTWR 241 QDGVSLSHNT QQWGDVLPDG NGTYQTWVAT RIRQGEEQRF TCYMEHSGNH GTHPVPSGKA 301 LVLQSQRTDF PYVSAAMPCF VIIIILCVPC CKKKTSAAEG PELVSLQVLD QHPVGTGDHR 361 DAAQLGFQPL MSATGSTGST EGT*
Amino acid sequence in FASTA format (without gap)
MICB*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- IMGT Alignment of alleles:
- Protein displays (MHC): G-LIKE-DOMAINs
- IMGT Collier de perles: G-LIKE-DOMAIN
- IMGT/3Dstructure-DB: 1je6
IMGT databases
External links
Nomenclature
- HGNC: 7091
Genome databases
- Entrez Gene: 4277
- GENATLAS:
- GeneCards: GC06P031574
- GDB: GDB:341912
- OMIM: 602436
Sequence databases
- EMBL: many entries (tables above)
- GenBank:
- DDBJ:
- Swiss-Prot:
- TrEMBL:
- NCBI:
Structure databases
- PDB: 1JE6
Created: 23/06/2005
Last updated: 02/10/2025 15:10
Authors: Emilie Carillon and Aurélie Frigoul
Editor: Chantal Ginestoux



Last updated: 02/10/2025 15:10
Authors: Emilie Carillon and Aurélie Frigoul
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT