
IMGT Repertoire (RPI)
IMGT RPI entry from gene to protein for Homo sapiens FCGR2A
Citing IMGT RPI entry for FCGR2A
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Homo sapiens FCGR2A
- IMGT gene definition: Fc fragment of IgG, low affinity IIa, receptor for (CD32)
Chromosomal localization
- Chromosome: 1
- Chromosomal localization: 1q23
Gene exon/intron organization
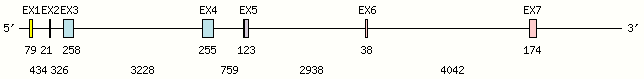
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 5
IMGT reference alleles
| Allele name | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Clone names | Accession numbers | Molecule type | ||
| FCGR2A*01 | F | M90721 (EX1) M90722 (EX2) M90723 (EX3) M90724 (EX4) M90725 (EX5) NT_004668 (EX6) M90727 (EX7) (1) |
gDNA | |
| FCGR2A*02 | F | J03619 | cDNA | |
| FCGR2A*03 | F | MGC:23887 | BC020823 (2) | cDNA |
| FCGR2A*04 | F | MGC:30032 | BC019931 (2) | cDNA |
| FCGR2A*05 | [1] (3) | gDNA | ||
IMGT reference sequences (in FASTA format) for the allele(s): FCGR2A*01 to FCGR2A*05
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele name | Gene functionality | IMGT reference sequences | ||
|---|---|---|---|---|
| Clone names | Accession numbers | Molecule type | ||
| FCGR2A*02 | F | X62572 (4) | cDNA | |
| M28697 (4) | cDNA | |||
Corresponding protein database accession numbers
| Allele name | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| FCGR2A*01 | M90721 (EX1) M90722 (EX2) M90723 (EX3) M90724 (EX4) M90725 (EX5) NT_004668 (EX6) M90727 (EX7) (1) |
SW: P12318 | 315 aa | N/A |
| FCGR2A*02 | X62572 (4) | 312 aa | N/A | |
| FCGR2A*03 | BC020823 (2) | 314 aa | N/A | |
| FCGR2A*04 | BC019931 (2) | 314 aa | N/A | |
| FCGR2A*05 | [1] (3) | 64 aa | N/A | |
IMGT notes:
- (1) The errors in the exon delimitations in M90721-M90725 are corrected in this IMGT entry and the corresponding FASTA sequences. M90726 which does not correspond to EX6 has been replaced with sequence extracted from NT_004668.
- (2) This allele has a 3 nucleotide deletion in the EX3 5' end a3.2-c2.1>del(3nt) ; A1.1>del (see IMGT numbering of additional codons (or amino acids) and corresponding nucleotides ; IMGT unique numbering for C-DOMAIN and C-LIKE-DOMAIN).
- (3) PCR product from position nucleotide 42 (aa N°15) to 108 nucleotides after the end of EX4.
- (4) Partial in 5' (7 nucleotides missing).
IMGT references:
- [1] Blood, Vol. 91, No 2, 656-662 (1998)..
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
FCGR2A*01: M91645(g) M90722(g) M90723(g) M90724(g) M90725(g) M90727(g) NT_004668(g)
Nucleotide sequence
1 atggagaccc aaatgtctca gaatgtatgt cccagaaacc tgtggctgct tcaaccattg 61 acagttttgc tgctgctggc ttctgcagac agtcaagctg cagctccccc aaaggctgtg 121 ctgaaacttg agcccccgtg gatcaacgtg ctccaggagg actctgtgac tctgacatgc 181 cagggggctc gcagccctga gagcgactcc attcagtggt tccacaatgg gaatctcatt 241 cccacccaca cgcagcccag ctacaggttc aaggccaaca acaatgacag cggggagtac 301 acgtgccaga ctggccagac cagcctcagc gaccctgtgc atctgactgt gctttccgaa 361 tggctggtgc tccagacccc tcacctggag ttccaggagg gagaaaccat catgctgagg 421 tgccacagct ggaaggacaa gcctctggtc aaggtcacat tcttccagaa tggaaaatcc 481 cagaaattct cccatttgga tcccaccttc tccatcccac aagcaaacca cagtcacagt 541 ggtgattacc actgcacagg aaacataggc tacacgctgt tctcatccaa gcctgtgacc 601 atcactgtcc aagtgcccag catgggcagc tcttcaccaa tggggatcat tgtggctgtg 661 gtcattgcga ctgctgtagc agccattgtt gctgctgtag tggccttgat ctactgcagg 721 aaaaagcgga tttcagccaa ttccactgat cctgtgaagg ctgcccaatt tgagccacct 781 ggacgtcaaa tgattgccat cagaaagaga caacttgaag aaaccaacaa tgactatgaa 841 acagctgacg gcggctacat gactctgaac cccagggcac ctactgacga tgataaaaac 901 atctacctga ctcttcctcc caacgaccat gtcaacagta ataactaa
Nucleotide sequence in FASTA format (without gaps)
FCGR2A*01
Amino acid sequence
1 METQMSQNVC PRNLWLLQPL TVLLLLASAD SQAAAPPKAV LKLEPPWINV LQEDSVTLTC 61 QGARSPESDS IQWFHNGNLI PTHTQPSYRF KANNNDSGEY TCQTGQTSLS DPVHLTVLSE 121 WLVLQTPHLE FQEGETIMLR CHSWKDKPLV KVTFFQNGKS QKFSHLDPTF SIPQANHSHS 181 GDYHCTGNIG YTLFSSKPVT ITVQVPSMGS SSPMGIIVAV VIATAVAAIV AAVVALIYCR 241 KKRISANSTD PVKAAQFEPP GRQMIAIRKR QLEETNNDYE TADGGYMTLN PRAPTDDDKN 301 IYLTLPPNDH VNSNN*
Amino acid sequence in FASTA format (without gap)
FCGR2A*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays: C-LIKE-DOMAIN
- IMGT Collier de perles: C-LIKE-DOMAIN
IMGT databases
External links
Nomenclature
- HGNC: 3616
Genome databases
- Entrez Gene: 2212
- GENATLAS: 254
- GeneCards: GC01P158252
- GDB: 119903
- OMIM: 146790
Sequence databases
- EMBL: M90721, M90722, M90723, M90724, M90725, M90727
- GenBank: M920721, M920722, M920723, M920724, M920725, M920727
- DDBJ: M920721, M920722, M920723, M920724, M920725, M920727
- Swiss-Prot: P12318
- TrEMBL:
- NCBI: NT_004668
Structure database
Created: 30/07/2004
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Laurent Douchy
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Laurent Douchy
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2025 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT