
IMGT Repertoire (RPI)
Other CD2 Family entries
IMGT RPI entry from gene to protein for Mus musculus SLAMF1
Citing IMGT RPI entry for SLAMF1
Duprat, E. et al.
IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs
of the immunoglobulin superfamily,
Recent Research Developments in Human Genetics, 2, 111-136 (2004)
 with permission from Research Signpost
with permission from Research Signpost
with permission from Research SignpostIMGT gene name and definition
- IMGT gene name: Mus musculus SLAMF1
- IMGT gene definition: signaling lymphocytic activation molecule family member 1
Chromosomal localization
- Chromosome: 1
- Chromosomal localization: 1 H3; 1 93.3cM
Gene exon/intron organization
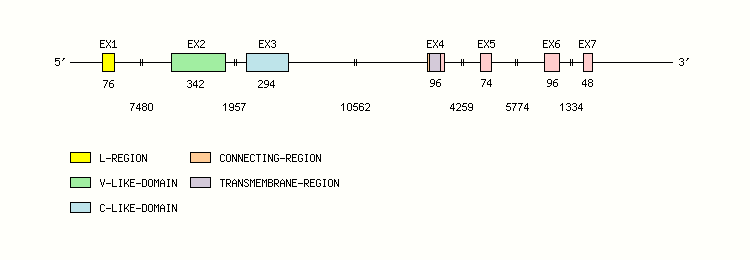
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Number of alleles: 7
IMGT reference alleles
| Allele names | Gene functionality | Strains | IMGT reference sequences | ||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||
| SLAMF1*01 | F | EX1 | AF164519 | gDNA | |
| EX2-3 | AF164520 | ||||
| EX4 | AF164521 | ||||
| EX5 | AF164522 | ||||
| EX6-7 | AF164523 | ||||
| SLAMF1*02 | F | C57BL/6J | EX1-7 | AK036429 | cDNA (1) |
| SLAMF1*03 | F | C57BL/6J | EX2-7 | AK016818 | cDNA (2) partial |
| SLAMF1*04 | F | BALB/c | EX1-7 | AF149791 | cDNA (3) |
| SLAMF1*05 | F | NOD | EX1-7 | AK172138 | cDNA (4) |
| SLAMF1*06 | F | EX1-7 | AB196798 | cDNA (5) | |
| SLAMF1*07 | F | EX1-7 | AB196797 | cDNA (6) | |
IMGT reference sequences (in FASTA format) for the allele(s): SLAMF1*01 to SLAMF1*07
- Nucleotide sequence in FASTA format with gaps according to the IMGT unique numbering
- Amino acid sequence in FASTA format with gaps according to the IMGT unique numbering
- Nucleotide sequence in FASTA format without gaps
- Amino acid sequence in FASTA format without gaps
Other sequences from the literature
| Allele names | Gene functionality | Strains | IMGT reference sequences | ||
|---|---|---|---|---|---|
| Exons | Accession numbers | Molecule type | |||
| SLAMF1*01 | F | C57BL/6J | EX3-7 | AK169547 | cDNA partial |
| NOD | EX1-7 | AK156445 | cDNA | ||
| EX1-7 | AF160990 | ||||
| C57BL/6J | EX1-5' | AK037780 | cDNA (7) splicing B | ||
| EX1-7 | NM_013730 | cDNA | |||
| SLAMF1*04 | F | EX1-7 | AB196796 | cDNA | |
| EX1-7 | BC117095 | ||||
| EX1-5' | AF149792 | cDNA splicing B | |||
| SLAMF1*06 | F | EX1-7 | BC117099 | cDNA | |
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| SLAMF1*01 | AF164519 | Tr:Q9QUM4 | 343 aa | 1 |
| AF164520 | ||||
| AF164521 | ||||
| AF164522 | ||||
| AF164523 | ||||
| NM_013730 | NP_038758 | 343 aa | 1 | |
| SLAMF1*02 | AK036429 | 343 aa | 1 | |
| SLAMF1*03 | AK016818 | Tr:Q9CUC8 | 267 aa | 1 partial |
| SLAMF1*04 | AF149791 | 343 aa | 1 | |
| SLAMF1*05 | AK172138 | 343 aa | 1 | |
| SLAMF1*06 | AB196798 | 343 aa | 1 | |
| SLAMF1*07 | AB196797 | 343 aa | 1 | |
IMGT notes:
- (1) In EX2[D1] a144>t, numbering according to unique numbering for V-DOMAIN and V-LIKE-DOMAIN.
- (2) No EX1 and partial EX2[D2]
- (3) In EX2[D1] a251>g, numbering according to unique numbering for V-DOMAIN and V-LIKE-DOMAIN.
- (4) In EX2[D1] a251>g; numbering according to unique numbering for V-DOMAIN and V-LIKE-DOMAIN. In EX5 a38>g, K13>E.
- (5) In EX2[D1] a251>g, numbering according to unique numbering for V-DOMAIN and V-LIKE-DOMAIN. In EX4 g62>a.
- (6) Nine differences.
- (7) Splicing B (326 aa). In EX5 there is no splice site and terminate after extending 31 codons beyond normal 3' splice site.
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
SLAMF1*01: AF164519(g)
Nucleotide sequence
1 atggatccca aaggatccct ttcctggaga atacttctgt ttctctccct ggcttttgag 61 ttgagctacg gaacaggtgg aggtgtgatg gattgcccag tgattctcca gaagctggga 121 caggacacgt ggctgcccct gacgaatgaa catcagataa ataagagcgt gaacaaaagt 181 gtccgcatcc tcgtcaccat ggcgacgtcc ccaggaagca aatccaacaa gaaaattgtg 241 tcttttgatc tctctaaagg gagctatcca gatcacctgg aggatggcta ccactttcaa 301 tcaaaaaacc tgagcctgaa gatcctcggg aacaggcggg agagtgaagg atggtacttg 361 gtgagcgtgg aggagaacgt ttctgttcag caattctgca agcagctgaa gctttatgaa 421 caggtctccc ctccagagat taaagtgcta aacaaaaccc aggagaacga gaatgggacc 481 tgcagcttgc tgttggcctg cacagtgaag aaaggggacc atgtgactta cagctggagt 541 gatgaggcag gcacccacct gctgagccga gccaaccgct cccacctcct gcacatcact 601 cttagcaacc agcatcaaga cagcatctac aactgcaccg caagcaaccc tgtcagcagt 661 atctctagga ccttcaacct atcatcgcaa gcatgcaagc aggaatcctc ctcagaatcg 721 agtccatgga tgcaatatac tcttgtacca ctgggggtcg ttataatctt catcctggtt 781 ttcacggcaa taataatgat gaaaagacaa ggtaaatcaa atcactgcca gccaccagtg 841 gaagaaaaaa gccttactat ttatgcccaa gtacagaaat cagggcctca agagaagaaa 901 cttcatgatg ccctaacaga tcaggacccc tgcacaacca tttatgtggc tgccacagag 961 cctgccccag agtctgtcca ggaaccaaac cccaccacag tttatgccag tgtgacactg 1021 ccagagagct ga
Nucleotide sequence in FASTA format (without gaps)
SLAMF1*01
Amino acid sequence
1 MDPKGSLSWR ILLFLSLAFE LSYGTGGGVM DCPVILQKLG QDTWLPLTNE HQINKSVNKS 61 VRILVTMATS PGSKSNKKIV SFDLSKGSYP DHLEDGYHFQ SKNLSLKILG NRRESEGWYL 121 VSVEENVSVQ QFCKQLKLYE QVSPPEIKVL NKTQENENGT CSLLLACTVK KGDHVTYSWS 181 DEAGTHLLSR ANRSHLLHIT LSNQHQDSIY NCTASNPVSS ISRTFNLSSQ ACKQESSSES 241 SPWMQYTLVP LGVVIIFILV FTAIIMMKRQ GKSNHCQPPV EEKSLTIYAQ VQKSGPQEKK 301 LHDALTDQDP CTTIYVAATE PAPESVQEPN PTTVYASVTL PES*
Amino acid sequence in FASTA format (without gap)
SLAMF1*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization:
- Alignment of alleles:
- Protein displays:
- IMGT Collier de perles: V-LIKE-DOMAIN, C-LIKE-DOMAIN
External links
Nomenclature
- HGNC:
Genome databases
Sequence database
- EMBL: AF164519, AF164520, AF164521, AF164522, AF164523, AK036429, AK016818, AF149791, AK172138, AB196798, AB196797, AK169547, AK156445, AF160990, AK037780, AB196796, BC117095, AF149792, BC117099
- GenBank: AF164519, AF164520, AF164521, AF164522, AF164523, AK036429, AK016818, AF149791, AK172138, AB196798, AB196797, AK169547, AK156445, AF160990, AK037780, AB196796, BC117095, AF149792, BC117099
- DDBJ: AF164519, AF164520, AF164521, AF164522, AF164523, AK036429, AK016818, AF149791, AK172138, AB196798, AB196797, AK169547, AK156445, AF160990, AK037780, AB196796, BC117095, AF149792, BC117099
- Swiss-Prot:
- TrEMBL: Q544K1, Q8CAU4, Q925P7, Q9CUC8, Q9QUM4
- NCBI: NM_013730, NP_038758
Structure databases
- PDB:
Created: 23/05/2007
Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux



Last updated: Friday, 22-Sep-2023 18:33:01 CEST
Authors: Phani Vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
- IMGT Home page
- IMGT Repertoire (IG and TR)
- IMGT Repertoire (MH)
- IMGT Repertoire (RPI)
- IMGT Index
- IMGT Scientific chart
- IMGT Education
- IMGT Latest news

© Copyright 1995-2025 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT