
IMGT Repertoire (MH)
IMGT MHC entry from gene to protein for Oncorhynchus mykiss MH1-C
IMGT gene name and definition
- IMGT gene name: Oncorhynchus mykiss MH1-C
- IMGT gene definition: major histocompatibility 1 alpha
Chromosomal localization
- Locus name: Oncorhynchus mykiss MHC
- Chromosome:
- Chromosomal localization:
Gene exon/intron organization
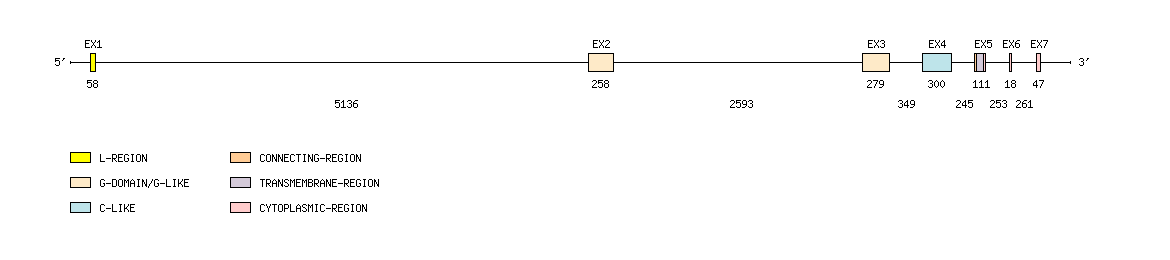
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Corresponding protein database accession numbers
| Allele names | IMGT/LIGM-DB | UniProt | Protein isoform | ||
|---|---|---|---|---|---|
| Accession numbers | Sequence lengths (nt) | Accession numbers | Sequence lengths (AA) | ||
| Oncmyk MH1-C*01 | AB162343 | 1071 | Q5FBT8 | 357 | |
| AY523659 | Q5FBT8 | 357 | |||
| HE603153 | 1038 | G4VUX0 | 346 | ||
| Oncmyk MH1-C*02 | DQ091773 | 1002 | Q2QF24 | 334 | |
| Oncmyk MH1-C*03 | AY523660 | 1071 | Q1XD50 | 357 | |
| Oncmyk MH1-C*04 | DQ091775 | 990 | Q2QF22 | 330 | |
| Oncmyk MH1-C*05 | AY523661 | 1077 | Q1XD49 | 359 | |
| Oncmyk MH1-C*06 | DQ091774 | 990 | Q2QF23 | 330 | |
| Oncmyk MH1-C*07 | AY523662 | 1077 | Q1XD48 | 359 | |
| Oncmyk MH1-C*08 | AY523663 | 1062 | Q1XD47 | 354 | |
| Oncmyk MH1-C*09 | AY523664 | 849 | Q1XD46 | 283 | |
| Oncmyk MH1-C*10 | AY523665 | 1080 | Q1XD45 | 360 | |
| Oncmyk MH1-C*11 | DQ926704 | 549 | Q005W9 | 183 | |
| Oncmyk MH1-C*12 | EU036640 | 531 | B1NQV0 | 177 | |
| Oncmyk MH1-C*13 | AY071854 | 1035 | Q8WM52 | 345 | |
| Oncmyk MH1-C*14 | HE603156 | 1035 | G4VUX3 | 345 | |
| HE603161 | G4VUX8 | 345 | |||
| HE603158 | G4VUX5 | 345 | |||
| HE603160 | G4VUX7 | 345 | |||
| Oncmyk MH1-C*15 | HE603154 | 1032 | G4VUX1 | 344 | |
| HE603155 | G4VUX2 | 344 | |||
| HE603159 | G4VUX6 | 344 | |||
| Oncmyk MH1-C*16 | HE603157 | 1035 | G4VUX4 | 345 | |
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
Oncmyk MH1-C*01: AB162343(g)
Coding region structure
Nucleotide sequence
1 atgaagggtt ttatgcttat gttcatggga ataggccacc tttatgaagc atttgctgtg 61 actcattccc tgacgcattt ctacaccgca tcttctgaag tttataactt cccagagttt 121 atggttgtgg ggatggtgga tggtgttcag atggttcact atgacagcaa cagccagaaa 181 gcggtgcccg aacaggactg gatgaagcag acagacgcag agttctggga gaaggagaga 241 gagaatttct tttattccca gcagtcattc aaagctgaag tcgctactct aaagcagcat 301 tttaaccaaa gtggaggagt ccacattctc cagtacatgt atggctgctc acgggatgat 361 gagactgaac agacagaggg gtttggacag ctgggttata atggggagaa cttccttgag 421 tacgacatga agacattaac ttggaaatct cgtaaacagc aagctaattt catgcaggat 481 gagtggaaca gtgacatcag tagactgggc ttctggaaga tctacttctc ccagacctgc 541 attgagtgtc tgaagaagca ggtggacaat gggaagcgca ctctgaggag gacagtccct 601 ccctcagtgt ctctgctcca gaagaccccc tcctctccag tgacctgcca cgctacaggt 661 ttctacccca gtggagtcat ggtgtcctgg cagaaagacg gacaagatca ccatgaagat 721 gtggagcatg gagagattct cttcaacgat gatggaacct tccagaaaag cacccacctc 781 acagtgatgc acgaggagag gaagaacaaa aattatcagt gtgtggttca ggtcactggt 841 atcaaggagg acttcatcaa ggttctgact gagtctgaga tccagaccaa ctggaaggac 901 ccagccccca acattatccc catcattgga gggatggtag cccccttcct ggtcgttgtt 961 gttgttgggg ttgttgtcat ttggaagaag aagaagagta agaaagggtt tgttccagcc 1021 agcacttctg acactgactc tgacaactct gggaaaggtc tcctgaagat ttga
Nucleotide sequence in FASTA format (without gaps)
Oncmyk MH1-C*01
Amino acid sequence
1 MKGFMLMFMG IGHLYEAFAV THSLTHFYTA SSEVYNFPEF MVVGMVDGVQ MVHYDSNSQK 61 AVPEQDWMKQ TDAEFWEKER ENFFYSQQSF KAEVATLKQH FNQSGGVHIL QYMYGCSRDD 121 ETEQTEGFGQ LGYNGENFLE YDMKTLTWKS RKQQANFMQD EWNSDISRLG FWKIYFSQTC 181 IECLKKQVDN GKRTLRRTVP PSVSLLQKTP SSPVTCHATG FYPSGVMVSW QKDGQDHHED 241 VEHGEILFND DGTFQKSTHL TVMHEERKNK NYQCVVQVTG IKEDFIKVLT ESEIQTNWKD 301 PAPNIIPIIG GMVAPFLVVV VVGVVVIWKK KKSKKGFVPA STSDTDSDNS GKGLLKI*
Amino acid sequence in FASTA format (without gap)
Oncmyk MH1-C*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Correspondence between nomenclatures (MHC): Teleostei
- Chromosomal localization: Vertebrate species (table)
- Correspondence between nomenclatures (MHC): Teleostei
- Protein displays (MHC): G-DOMAIN
- Alignment of alleles:
- Strand and loop lengths (MHC): G-DOMAIN
- Collier de perles (MHC): G-DOMAIN
- Numbering: G-DOMAIN
- Sequence and 3D structure identification and description: Label definitions for IG, TR and MHC
- Nomenclature: IMGT description of mutations
IMGT Scientific chart
IMGT Index
- IMGT Index: Allele
- Tutorials: Présentation du complexe majeur d'histocompatibilité
- IMGT/3Dstructure-DB:
IMGT Education
IMGT databases
External links
Nomenclature
- HGNC:
Genome databases
- NCBI Gene:
- GENATLAS:
- GeneCards:
- GDB:
- OMIM:
Sequence databases
Structure database
- PDB:
Created: 08/02/2012
Last updated: 02/10/2025 15:10
Authors: Saida Saljoqi and Marie-Paule Lefranc
Editor: Chantal Ginestoux


Last updated: 02/10/2025 15:10
Authors: Saida Saljoqi and Marie-Paule Lefranc
Editor: Chantal Ginestoux
IMGT Home page |
IMGT Repertoire (IG and TR) |
IMGT Repertoire (MH) |
IMGT Repertoire (RPI) |
IMGT Index |
IMGT Scientific chart |
IMGT Education |
IMGT Latest news ![]()
© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT