
IMGT Repertoire (MH)
Other MHC entries
- Mus musculus: MH2-AB
IMGT MHC entry from gene to protein for Mus musculus MH2-AA
IMGT gene name and definition
- IMGT gene name: Mus musculus MH2-AA
- IMGT gene definition: histocompatibility 2, class II antigen A, alpha
Chromosomal localization
- Locus name:
- Chromosome: 17
- Chromosomal localization: 17B1; 17 18.65cM
Gene exon/intron organization
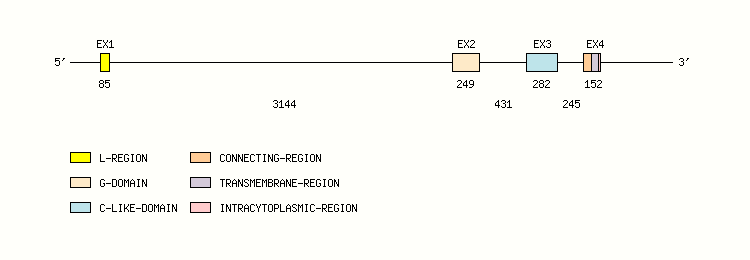
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Corresponding protein database accession numbers
| Allele name | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| MH2-AA*04 | K01923 | P04228 | 256aa | 1 |
| MH2-AA*05 | AK170931 | Tr:Q549Q2 | 243aa | 1 |
| MH2-AA*08 | BC019721 | P14434 | 256aa | 1 |
| MH2-AA*10 | AF065910 | Tr:Q549Q3 | 233aa | 1 |
| MH2-AA*12 | X52643 | P23150 | 254aa | 1 |
| MH2-AA*14 | K01925 | P04227 | 221aa | 1 |
| MH2-AA*16 | M11358 | P14437 | 233aa | 1 |
IMGT references:
- [1] Carninci P. et al., Meth. Enzymol. 303, 19-44 (1999). PMID:10349636
- [2] Strausberg R.L. et al., Proc. Natl. Acad. Sci. U.S.A. 99, 16899-16903 (2002). PMID:12477932
- [3] Benoist C.O. et al., Cell 34, 169-177 (1983). PMID:6309407
- [4] Landais D. et al., Proc. Natl. Acad. Sci. U.S.A. 82, 2930-2934 (1985). PMID:2581258
- [5] Bishop G.A. et al., Immunogenetics 28, 184-192 (1988). PMID:3137158
- [6] Acha-Orbea H. and Scarpellino L. Immunogenetics 34, 57-59 (1991). PMID:1855817
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
MH2-AA*01: NC_000083(g)
Nucleotide sequence
1 atgccgcgca gcagagctct gattctgggg gtcctcgccc tgaccaccat gctcagcctc 61 tgtggaggtg aagacgacat tgaggccgac cacgtaggca cctatggtat aagtgtatat 121 cagtctcctg gagacattgg ccagtacaca tttgaatttg atggtgatga gttgttctat 181 gtggacttgg ataagaagga gactgtctgg atgcttcctg agtttggcca attggcaagc 241 tttgaccccc aaggtggact gcaaaacata gctgtagtaa aacacaactc gcgagtattg 301 actaagaggt caaattccac cccagctacc aatgaggctc ctcaagcgac tgtgttcccc 361 aagtcccctg tgctgctggg tcagcccaac accctcatct gctttgtgga caacatcttc 421 cctcctgtga tcaacatcac atggctcaga aatagcaagt cagtcgcaga cggtgtttat 481 gagaccagct tcttcgtcaa ccgtgactat tccttccaca agctgtctta tctcaccttc 541 atcccttctg acgatgacat ttatgactgc aaggtggaac actggggcct ggaggagccg 601 gttctgaaac actgggaacc tgagattcca gcccccatgt cagagctgac agagactgtg 661 gtctgtgccc tggggttgtc tgtgggcctt gtgggcatcg tggtgggcac catcttcatc 721 attcaaggcc tgcgatcagg tggcacctcc agacacccag ggcctttatg a
Nucleotide sequence in FASTA format (without gaps)
MH2-AA*01
Amino acid sequence
1 MPRSRALILG VLALTTMLSL CGGEDDIEAD HVGTYGISVY QSPGDIGQYT FEFDGDELFY 61 VDLDKKETVW MLPEFGQLAS FDPQGGLQNI AVVKHNSRVL TKRSNSTPAT NEAPQATVFP 121 KSPVLLGQPN TLICFVDNIF PPVINITWLR NSKSVADGVY ETSFFVNRDY SFHKLSYLTF 181 IPSDDDIYDC KVEHWGLEEP VLKHWEPEIP APMSELTETV VCALGLSVGL VGIVVGTIFI 241 IQGLRSGGTS RHPGPL*
Amino acid sequence in FASTA format (without gap)
MH2-AA*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization: Vertebrate species (table)
- Protein displays (MHC): G-DOMAIN
- Alignment of alleles:
- Strand and loop lengths (MHC): G-DOMAIN
- Collier de perles (MHC): G-DOMAIN
- Numbering: G-DOMAIN
- Sequence and 3D structure identification and description: Label definitions for IG, TR and MHC
- Nomenclature: IMGT description of mutations
IMGT Scientific chart
IMGT Index
Created: 18/10/2006
Last updated: 02/10/2025 15:10
Authors: Phani vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux


Last updated: 02/10/2025 15:10
Authors: Phani vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
IMGT Home page |
IMGT Repertoire (IG and TR) |
IMGT Repertoire (MH) |
IMGT Repertoire (RPI) |
IMGT Index |
IMGT Scientific chart |
IMGT Education |
IMGT Latest news ![]()
© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT