
IMGT Repertoire (MH)
Other MHC entries
- Mus musculus: MH2-EB
IMGT MHC entry from gene to protein for Mus musculus MH2-EA
IMGT gene name and definition
- IMGT gene name: Mus musculus MH2-EA
- IMGT gene definition: histocompatibility 2, class II antigen E, alpha
Chromosomal localization
- Locus name:
- Chromosome: 17
- Chromosomal localization: 17B1; 17 18.7cM
Gene exon/intron organization
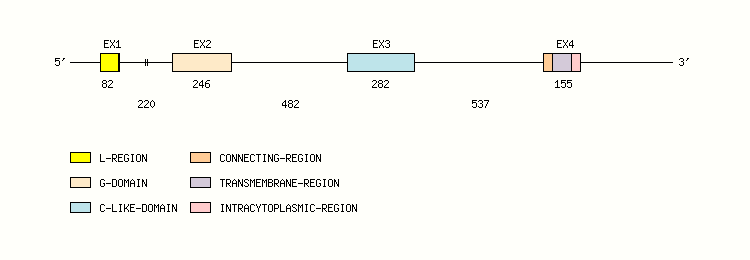
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Corresponding protein database accession numbers
| Allele name | Accession numbers | Number of amino acids | Protein isoform | |
|---|---|---|---|---|
| Nucleotide databases | Protein databases | |||
| MH2-EA*01 | K00971 | Sw: P01904 | 255aa | |
| MH2-EA*04 | BC106107 | Tr: Q3KQP6 | 255aa | |
| MH2-EA*06 | V00833, V00834 | Sw: P04224 | 255aa | |
| MH2-EA*07 | U13648 | Tr: Q31092 | 255aa | |
| MH2-EA*08 | NM_010381 | NP_034511 | 255aa | |
IMGT notes:
- (1) No EX1 and partial EX4.
- (2) Sequence has been extracted from the genome annotation reference sequence NT_039649. Partial no EX1.
IMGT references:
- [1] Hyldig-Nielsen, J.J. et al, Nucleic Acids Res. 11, 5055-5071 (1983). PMID:6308570
- [2] Cao, T.M. et al, Proc. Natl. Acad. Sci. U.S.A. 100, 11571-11576 (2003). PMID:14504392
- [3] Mathis, D.J. et al, Cell 32, 745-754 (1983). PMID:6403249
- [4] Tacchini-Cottier, F. et al, Int. Immunol. 7, 1459-1471 (1995).. PMID:7495754
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
MH2-EA*02: K00971(g)
Nucleotide sequence
1 atggccacaa ttggagccct gctgttaaga tttttcttca ttgctgttct gatgagctcc 61 cagaagtcat gggctatcaa agaggaacac accatcatcc aggcggagtt ctatctttta 121 ccagacaaac gtggagagtt tatgtttgac tttgacggcg atgagatttt ccatgtagac 181 attgaaaagt cagagaccat ctggagactt gaagaatttg caaagtttgc cagctttgag 241 gctcagggtg cactggctaa tatagctgtg gacaaagcta acctggatgt catgaaagag 301 cgttccaaca acactccaga tgccaacgtg gccccagagg tgactgtact ctccagaagc 361 cctgtgaacc tgggagagcc caacatcctc atctgtttca ttgacaagtt ctcccctcca 421 gtggtcaatg tcacctggtt ccggaatgga cggcctgtca ccgaaggcgt gtcagagaca 481 gtgtttctcc cgagggacga tcacctcttc cgcaaattcc actatctgac cttcctgccc 541 tccacagatg atttctatga ctgtgaggtg gatcactggg gtttggagga gcctctgcgg 601 aagcactggg agtttgaaga gaaaaccctc ctcccagaaa ctacagagaa tgtcgtgtgt 661 gctcttgggt tgtttgtggg tctggtgggc atcgttgtgg ggattatcct catcatgaag 721 ggtattaaaa aacgcaatgt tgtagaacgc cgacaaggag ccctgtga
Nucleotide sequence in FASTA format (without gaps)
MH2-EA*02
Amino acid sequence
1 MATIGALLLR FFFIAVLMSS QKSWAIKEEH TIIQAEFYLL PDKRGEFMFD FDGDEIFHVD 61 IEKSETIWRL EEFAKFASFE AQGALANIAV DKANLDVMKE RSNNTPDANV APEVTVLSRS 121 PVNLGEPNIL ICFIDKFSPP VVNVTWFRNG RPVTEGVSET VFLPRDDHLF RKFHYLTFLP 181 STDDFYDCEV DHWGLEEPLR KHWEFEEKTL LPETTENVVC ALGLFVGLVG IVVGIILIMK 241 GIKKRNVVER RQGAL*
Amino acid sequence in FASTA format (without gap)
MH2-EA*02
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization: Vertebrate species (table)
- Protein displays (MHC): G-DOMAIN
- Alignment of alleles:
- Strand and loop lengths (MHC): G-DOMAIN
- Collier de perles (MHC): G-DOMAIN
- Numbering: G-DOMAIN
- Sequence and 3D structure identification and description: Label definitions for IG, TR and MHC
- Nomenclature: IMGT description of mutations
IMGT Scientific chart
IMGT Index
Created: 18/10/2006
Last updated: 02/10/2025 15:10
Authors: Phani vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux


Last updated: 02/10/2025 15:10
Authors: Phani vijay Garapati and Marie-Paule Lefranc
Editor: Chantal Ginestoux
IMGT Home page |
IMGT Repertoire (IG and TR) |
IMGT Repertoire (MH) |
IMGT Repertoire (RPI) |
IMGT Index |
IMGT Scientific chart |
IMGT Education |
IMGT Latest news ![]()
© Copyright 1995-2026 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT