
IMGT Repertoire (MH)
IMGT MHC entry from gene to protein for Mus musculus MH1-K1
Citing IMGT MHC entry for MH1-K1
Lefranc, M.-P., Duprat, E., Kaas, Q., Tranne, M., Thiriot, A. and Lefranc, G.
IMGT unique numbering for MHC groove G-DOMAIN and MHC superfamily (MhcSF) G-LIKE-DOMAIN,
Dev. Comp. Immunol., 29, 917-938 (2005). PMID: 15936075
 with permission from Elsevier
with permission from Elsevier
with permission from Elsevier
IMGT gene name and definition
- IMGT gene name: Mus musculus MH1-K1
- IMGT gene definition: major histocompatibility complex (MHC) class I, antigen K1
Chromosomal localization
- Locus name:
- Chromosome: 17
- Chromosomal localization: 17p18.44
Gene exon/intron organization
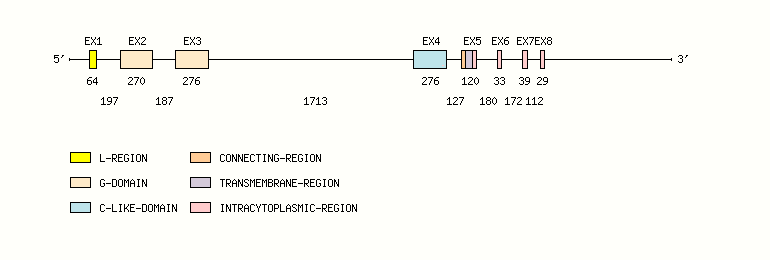
Legend:
- Length of the exons and introns are in base pairs.
- Colors are according to IMGT Color menu for regions and domains
Corresponding protein database accession numbers
| Allele names | Accession numbers | Number of coding nucleotides | Number of coding amino acids | Protein isoform | |
|---|---|---|---|---|---|
| Nucleotide databases EMBL | Protein databases | ||||
| MH1-K1*01 | V00746/V00747 | P01901 | 1107pb | 369aa | A |
| U47328 | 1107pb | 369aa | |||
| AK153419 | Q7JJ15 | 1107pb | 369aa | ||
| AF100956 | O35613 | 1107pb | 369aa | ||
| NM_001001892 | None | 1107pb | 369aa | ||
| AK150967 | 1107pb | 369aa | |||
| AK168517 | Q3TH01 | 1080pb | 360aa | B | |
| MH1-K1*02 | J00400 | P01901 | 849pb | 283aa | A |
| MH1-K1*03 | U47329 | P01902 | 1104pb | 368aa | A |
| L36065 | 1104pb | 368aa | |||
| DQ346646 | Q5KTQ2 | 1104pb | 368aa | ||
| DQ346647 | 1104pb | 368aa | |||
| DQ346648 | 1104pb | 368aa | |||
| MH1-K1*04 | X01815 | O35641 | 1104pb | 368aa | A |
| MH1-K1*05 | J00402 | P01902 | 1104pb | 368aa | A |
| MH1-K1*06 | J00393 | Q31154 | 624pb | 208aa | C |
| MH1-K1*07 | M18525 | Q31173 | 1207pb | 402aa | A |
| MH1-K1*08 | X01652 | P04223 | 1307pb | 435aa | A |
| M18964 | 1080pb | 360aa | |||
| U47330 | 1079pb | 359aa | B | ||
| MH1-K1*09 | M11975 | P04223 | 1044pb | 348aa | B |
| MH1-K1*10 | M58156 | Q31172 | 1107pb | 369aa | A |
| MH1-K1*11 | L23494 | Q31141 | 1080pb | 360aa | B |
| MH1-K1*12 | M69070 | Q61894 | 1107pb | 369aa | A |
| MH1-K1*13 | M14827 | P14428 | 984pb | 328aa | A |
| M26858 | O19468 | 45pb | 15aa | ||
| M26859 | None | 43pb | 14aa | ||
| X00172 | P03991 | 333pb | 111aa | ||
| K01762 | Q31193 | 306pb | 102aa | B | |
| MH1-K1*14 | M69071 | Q61895 | 1104pb | 368aa | A |
| MH1-K1*15 | M60168 | Q64272 | 1104pb | 368aa | A |
| MH1-K1*16 | M14825 | P03991 | 1104pb | 368aa | A |
| MH1-K1*17 | L23495 | Q31142 | 1107pb | 369aa | A |
| MH1-K1*18 | M69073 | Q61896 | 1104pb | 368aa | A |
| MH1-K1*19 | L36310 | Q31634 | 1104pb | 368aa | A |
| L36311 | Q31614 | 1104pb | 368aa | ||
| L36312 | 1104pb | 368aa | |||
| MH1-K1*20 | J00401 | Q31190 | 276pb | 92aa | |
| MH1-K1*21 | M12935 | Q95555 | 276pb | 92aa | |
| MH1-K1*22 | M13200 | Q31189 | 274pb | 91aa | |
| MH1-K1*23 | L36306 | Q31614 | 1104pb | 368aa | A |
| L36307 | 1104pb | 368aa | |||
| L36309 | 1104pb | 368aa | |||
| MH1-K1*24 | J00394 | P01897 | 476pb | 158aa | A |
| MH1-K1*25 | J00395 | Q31156 | 492pb | 164aa | A |
| MH1-K1*26 | K01182 | Q31191 | 1065pb | 355aa | A |
| MH1-K1*27 | M34932 | P04223 | 877pb | 292aa | |
| MH1-K1*28 | AB114280 | Q5KTQ2 | 1104pb | 368aa | A |
| MH1-K1*29 | L36308 | Q31148 | 1104pb | 368aa | A |
| MH1-K1*30 | BC054430 | Q7TN03 | 1055pb | 351aa | A |
| MH1-K1*31 | AB114296 | Q5KTQ0 | 1104pb | 368aa | |
| MH1-K1*32 | AB121050 | Q1XIR8 | 276pb | 92aa | |
| MH1-K1*33 | AF470231 | Q3TVI9 | 810pb | 270aa | |
| MH1-K1*34 | AK160102 | Q3TVI9 | 808pb | 269aa | A |
| MH1-K1*35 | AY496688 | Q6RJ37 | 1044pb | 348aa | A |
| MH1-K1*36 | BC011306 | Q921P3 | 858pb | 286aa | A |
| MH1-K1*37 | M60169 | Q61642 | 1104pb | 368aa | A |
| MH1-K1*38 | AK150790 | Q3UBW0 | 1039pb | 346aa | D |
| MH1-K1*39 | AK159321 | None | 885pb | 295aa | |
| MH1-K1*40 | AY989882 | None | 562pb | 187aa | A |
| MH1-K1*41 | S70184 | Q31290 | 794pb | 264aa | A |
| partial sequences | M11847 | None | 19pb | 6aa | |
| U55818 | O19449 | 218pb | 72aa | ||
| M23403 | None | 54pb | 18aa | ||
| M23399 | 69pb | 23aa | |||
| M23401 | 82pb | 27aa | |||
| M23402 | 54pb | 18aa | |||
IMGT notes:
- (1) Partial (5' part of EX2 missing).
- (2) In-frame DELETION at the 3' end of CYTOPLASMIC-REGION (R3>del(1AA)).
- (3) Partial (5' part of EX3 missing). In-frame DELETION at the 3' end of C-LIKE (L118>del(1AA)) and in-frame DELETION at the end of TRANSMEMBRANE-REGION (M26>del(1AA)). ORF due to three additional amino acids at the 3' end of C-LIKE owing to a mutation in the DONOR-SPLICE which leads to an alternative splicing. 8 amino acids in 5' of EX8 are missing due to an alternative splicing (EX8 is represented by only 2 nucleotides).
- (4) Partial (5' part of EX1 missing). 8 amino acids in 5' of EX8 are missing due to an alternative splicing (EX8 is represented by only 2 nucleotides).
- (5) 8 amino acids in 5' of EX8 are missing due to an alternative splicing (EX8 is represented by only 2 nucleotides).
- (6) Partial (5' part EX2 missing). In-frame DELETION at the 3' end of TRANSMEMBRANE-REGION (K25>del(1AA)).
- (7) In-frame DELETION at the 3' end of TRANSMEMBRANE-REGION (M26>del(1AA)).
- (8) In-frame DELETION at the 3' end of TRANSMEMBRANE-REGION (K25>del(1AA)).
- (9) Pseudogene due to a Out-of-frame DELETION in 5' of G-ALPHA2 (del(2nt)#, S2>del#).
- (10) Partial (5' part of EX3 missing). In-frame DELETION at the 3' end of TRANSMEMBRANE-REGION (M26>del(1AA)). 8 amino acids in 5' of EX8 are missing due to an alternative splicing (EX8 is represented by only 2 nucleotides).
- (11) Partial (5' part of EX4 missing). In-frame DELETION at the 3' end of CYTOPLASMIC-REGION (R3>del(1AA)).
- (12) Pseudogene due to several out-of-frame DELETIONs comprising a total of 25 nucleotides in the G-ALPHA1-DOMAIN. In-frame DELETION at the 3' end of TRANSMEMBRANE-REGION (R38>del(1AA)).
- (13) Partial (3' part of EX5 missing).
- (14) Incomplete intron sequence (series of "N") in AB114280.1 (3184pb, 12/01/05). In-frame DELETION at the 3' end of CYTOPLASMIC-REGION (R3>del(1AA)).
- (15) Partial (5' part of EX1 missing). In-frame DELETION at the 3' end of TRANSMEMBRANE-REGION (K25>del(1AA)).
- (16) Incomplete intron sequence (series of "N") in AB114296.1 (3186pb, 12/01/05). In-frame DELETION at the 3' end of CYTOPLASMIC-REGION (R3>del(1AA)).
- (17) Partial (3' part of EX4 missing).
- (18) Pseudogene due to a DELETION of 60 nucleotides in the L-REGION (V2-A21>del(20AA)). In-frame DELETION at the 3' end of CYTOPLASMIC-REGION (R3>del(1AA)).
- (19) ORF due to an incomplete splicing at the 3' end of EX6. It is possible that the sequence is an immature cDNA.
- (20) Pseudogene due to a out-of-frame DELETION in the G-ALPHA2 leading to a STOP-CODON (del(1nt)#, Y28>del#).
- (21) Pseudogene due to no EX2 (G-ALPHA1) and no EX3 (G-ALPHA2).
- (22) Partial (5' part of EX1 missing). Pseudogene due to a DELETION of EX3 (G-ALPHA2). In-frame DELETION at the 3' end of CYTOPLASMIC-REGION (R3>del(1AA)).
- (23) Partial (5' part of EX7 missing).
- (24) Partial (5' part of EX4 missing). In-frame DELETION at the 3' end of TRANSMEMBRANE-REGION (K25>del(1AA)).
Genomic sequence
Coding region sequence
The coding region (CODING-REGION)
sequence starts from INIT-CODON
(or its encoded amino acid) to STOP-CODON
(not included).
The nucleotide sequence is extracted from cDNA (c) sequences and/or is
built by artificial exon joining from genomic DNA (g) sequences.
The amino acid sequence is the translation of the nucleotide sequence.
MH1-K1*01: U47328(c)
Nucleotide sequence
1 atggtaccgt gcacgctgct cctgctgttg gcggccgccc tggctccgac tcagacccgc 61 gcgggcccac actcgctgag gtatttcgtc accgccgtgt cccggcccgg cctcggggag 121 ccccggtaca tggaagtcgg ctacgtggac gacacggagt tcgtgcgctt cgacagcgac 181 gcggagaatc cgagatatga gccgcgggcg cggtggatgg agcaggaggg gcccgagtat 241 tgggagcggg agacacagaa agccaagggc aatgagcaga gtttccgagt ggacctgagg 301 accctgctcg gctactacaa ccagagcaag ggcggctctc acactattca ggtgatctct 361 ggctgtgaag tggggtccga cgggcgactc ctccgcgggt accagcagta cgcctacgac 421 ggctgcgatt acatcgccct gaacgaagac ctgaaaacgt ggacggcggc ggacatggcg 481 gcgctgatca ccaaacacaa gtgggagcag gctggtgaag cagagagact cagggcctac 541 ctggagggca cgtgcgtgga gtggctccgc agatacctga agaacgggaa cgcgacgctg 601 ctgcgcacag attccccaaa ggcccatgtg acccatcaca gcagacctga agataaagtc 661 accctgaggt gctgggccct gggcttctac cctgctgaca tcaccctgac ctggcagttg 721 aatggggagg agctgatcca ggacatggag cttgtggaga ccaggcctgc aggggatgga 781 accttccaga agtgggcatc tgtggtggtg cctcttggga aggagcagta ttacacatgc 841 catgtgtacc atcaggggct gcctgagccc ctcaccctga gatgggagcc tcctccatcc 901 actgtctcca acatggcgac cgttgctgtt ctggttgtcc ttggagctgc aatagtcact 961 ggagctgtgg tggcttttgt gatgaagatg agaaggagaa acacaggtgg aaaaggaggg 1021 gactatgctc tggctccagg ctcccagacc tctgatctgt ctctcccaga ttgtaaagtg 1081 atggttcatg accctcattc tctagcgtga
Nucleotide sequence in FASTA format (without gaps)
MH1-K1*01
Amino acid sequence
1 MVPCTLLLLL AAALAPTQTR AGPHSLRYFV TAVSRPGLGE PRYMEVGYVD DTEFVRFDSD 61 AENPRYEPRA RWMEQEGPEY WERETQKAKG NEQSFRVDLR TLLGYYNQSK GGSHTIQVIS 121 GCEVGSDGRL LRGYQQYAYD GCDYIALNED LKTWTAADMA ALITKHKWEQ AGEAERLRAY 181 LEGTCVEWLR RYLKNGNATL LRTDSPKAHV THHSRPEDKV TLRCWALGFY PADITLTWQL 241 NGEELIQDME LVETRPAGDG TFQKWASVVV PLGKEQYYTC HVYHQGLPEP LTLRWEPPPS 301 TVSNMATVAV LVVLGAAIVT GAVVAFVMKM RRRNTGGKGG DYALAPGSQT SDLSLPDCKV 361 MVHDPHSLA*
Amino acid sequence in FASTA format (without gap)
MH1-K1*01
Legend:
- Colors are according to IMGT Color menu for regions and domains
- Nucleotide and amino acid letters (in bold) in purple, green or blue are according to IMGT Color menu for splicing types.
IMGT links
IMGT Repertoire
- Chromosomal localization: Vertebrate species (table)
- Protein displays (MHC): G-DOMAIN, C-LIKE-DOMAIN
- Alignment of alleles:
- Strand and loop lengths (MHC): G-DOMAIN, C-LIKE-DOMAIN
- Collier de perles (MHC): G-DOMAIN, C-LIKE-DOMAIN
IMGT Scientific chart
- Numbering: G-DOMAIN, C-LIKE-DOMAIN
- Sequence and 3D structure identification and description: Label definitions for IG, TR and MHC, Standardized keywords and labels for IG, TR, MHC, RPI and FPIA
- Nomenclature: IMGT description of mutations
IMGT Index
IMGT Education
- Tutorials: Présentation du complexe majeur d'histocompatibilité, La superfamille des immunoglobulines (IgSF), La superfamille du complexe majeur d'histocompatibilité (MhcSF)
IMGT databases
External links
Nomenclature
- MGI: 95904
Genome databases
- Entrez Gene: 14972
Sequence databases
- EMBL: many entries (tables above)
- GenBank: many entries (tables above)
- DDBJ: many entries (tables above)
- Swiss-Prot: many entries (tables above)
- TrEMBL: many entries (tables above)
- NCBI: many entries (tables above)
Structure databases
Created: 03/12/2007
Last updated: Friday, 22-Sep-2023 18:31:35 CEST
Authors: Elodie Gemrot and Marie-Paule Lefranc
Editor: Chantal Ginestoux


Last updated: Friday, 22-Sep-2023 18:31:35 CEST
Authors: Elodie Gemrot and Marie-Paule Lefranc
Editor: Chantal Ginestoux
IMGT Home page |
IMGT Repertoire (IG and TR) |
IMGT Repertoire (MH) |
IMGT Repertoire (RPI) |
IMGT Index |
IMGT Scientific chart |
IMGT Education |
IMGT Latest news ![]()
© Copyright 1995-2025 IMGT®, the international ImMunoGeneTics information system® | Terms of use | About us | Contact us | Citing IMGT